
Have you built a RAG system according to a tutorial, and it seems to give you correct answers in around 60-80% of cases? It’s normal. Many people have such a problem.
Table of Contents
- Semantic Search
- Query Expansion
- HyDE - Hypothetical Document Embeddings
- Keyword search - BM25
- Self query - extracting metadata
- Parent Document Retrieval
- Reranking
- The problem with all retrieval algorithms
Here, I explain how RAG systems retrieve data and what techniques we can use to improve the quality of answers.
I will focus on the Retrieval part of the Retrieval Augmented Generation because it has the biggest impact. After all, even the best language model won’t produce a correct answer if the data it receives is incorrect.
Semantic Search
Let’s start with the basics. Every RAG system starts with a vector database, an embedding model, and a large language model.
I need to explain the semantic search steps in detail because most other techniques are built on top of the semantic search.
First, you take a bunch of documents, split them into chunks, calculate chunk embeddings, and store them with the text in a vector database (in some databases, embedding calculation happens internally). The ingestion process will remain unchanged for most of the advanced techniques explained below.
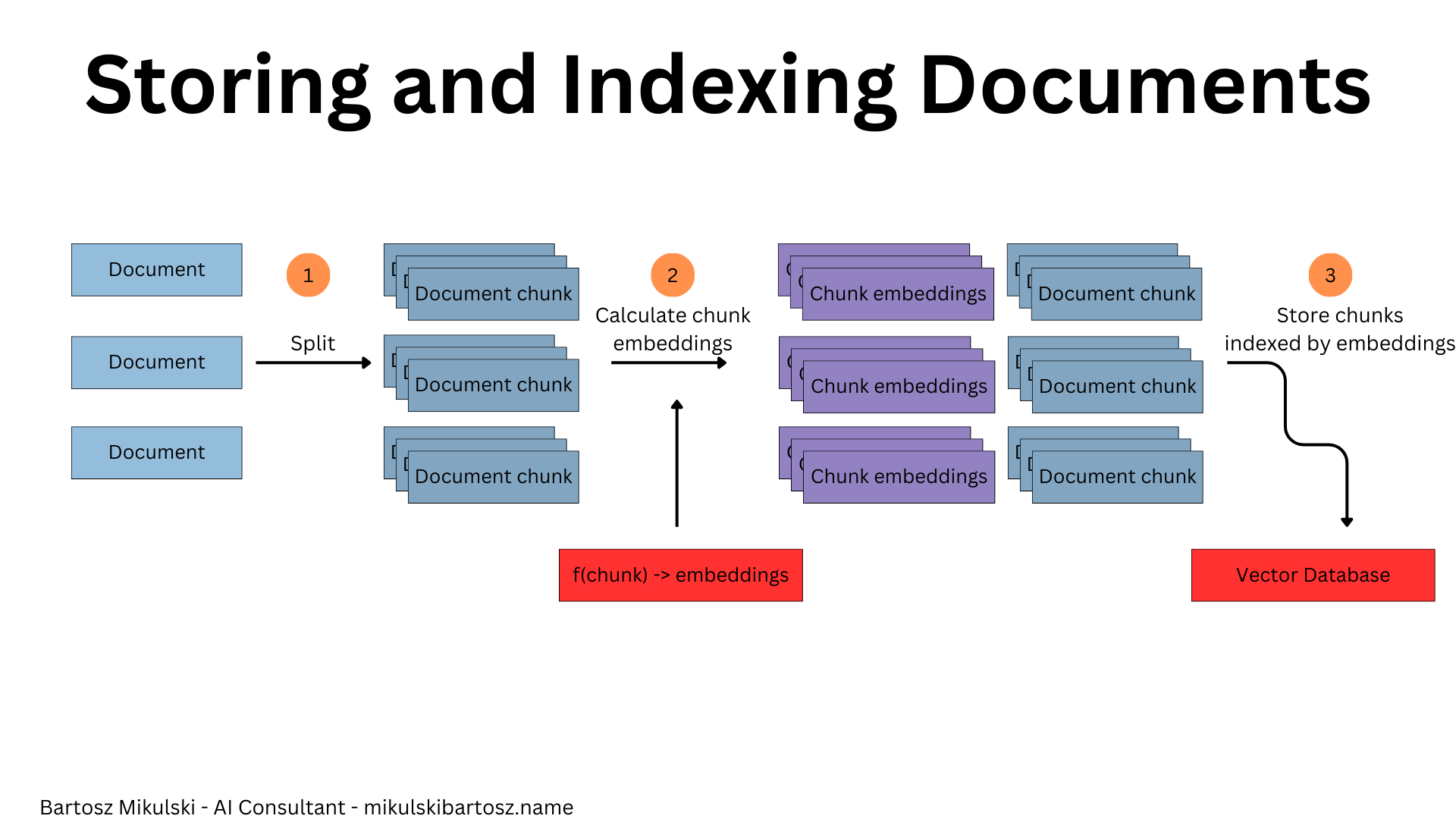
When you want to retrieve data from the database, you take the user’s question, calculate the question’s embeddings to get a search vector, find similar vectors in the vector database, and return the corresponding text documents.
Ultimately, you pass the questions and the retrieved documents to an LLM, and the AI model synthesizes an answer.
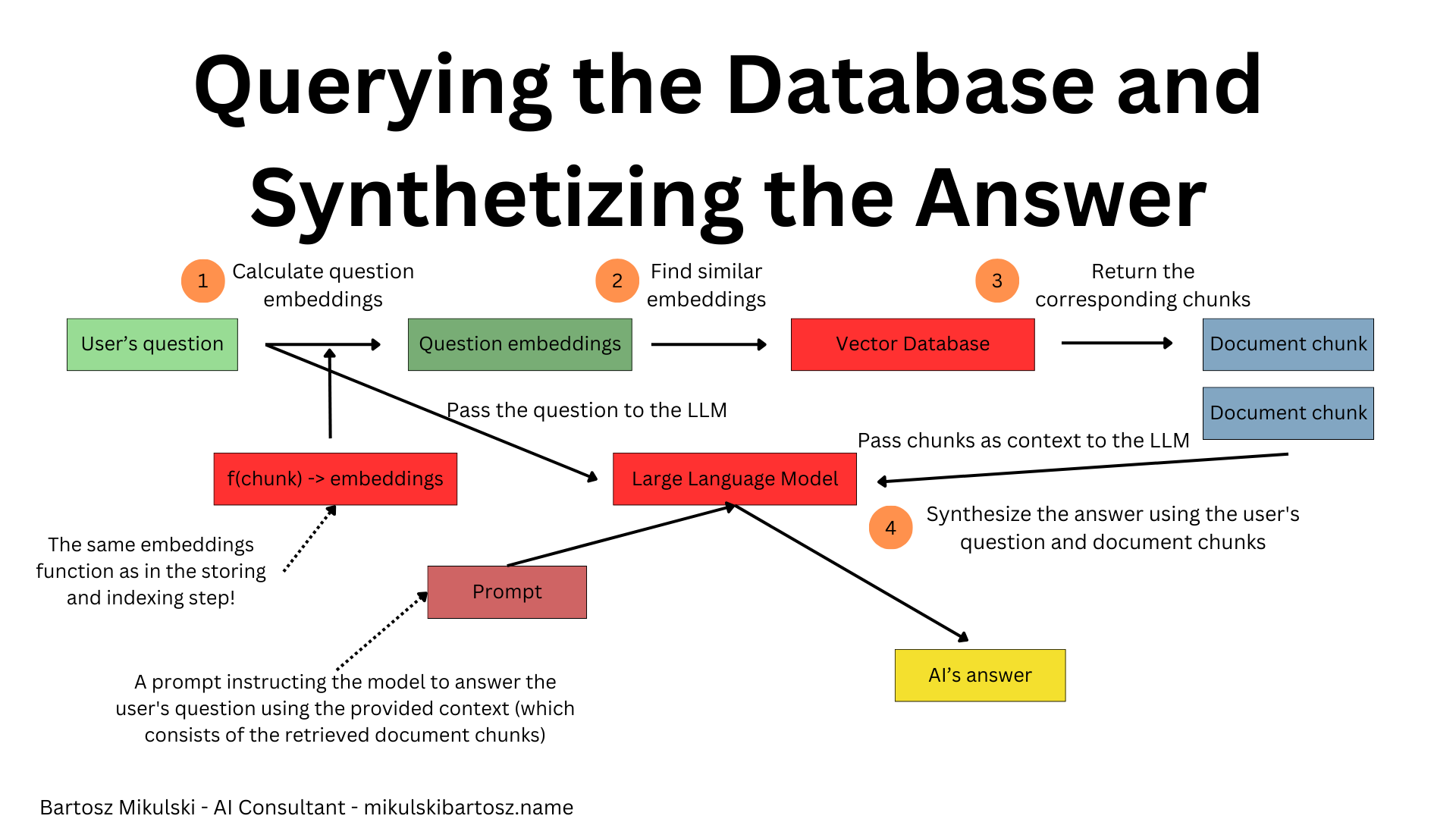
How does the vector similarity work?
The creators of the embedding models train them to make the numeric representation of words similar if the meaning of the words is similar too. Because of that, when we calculate the embeddings of a given text and the embeddings of a question answered by the text, their respective embedding vectors should be similar.
What does similar mean? In mathematics, several functions are used to calculate the similarity between vectors. One is the cosine similarity, which is computed as the dot product of the vectors divided by the product of their magnitudes. We get a value between -1 and 1, where 1 means both vectors are the same, and -1 indicates opposite vectors.
Query Expansion
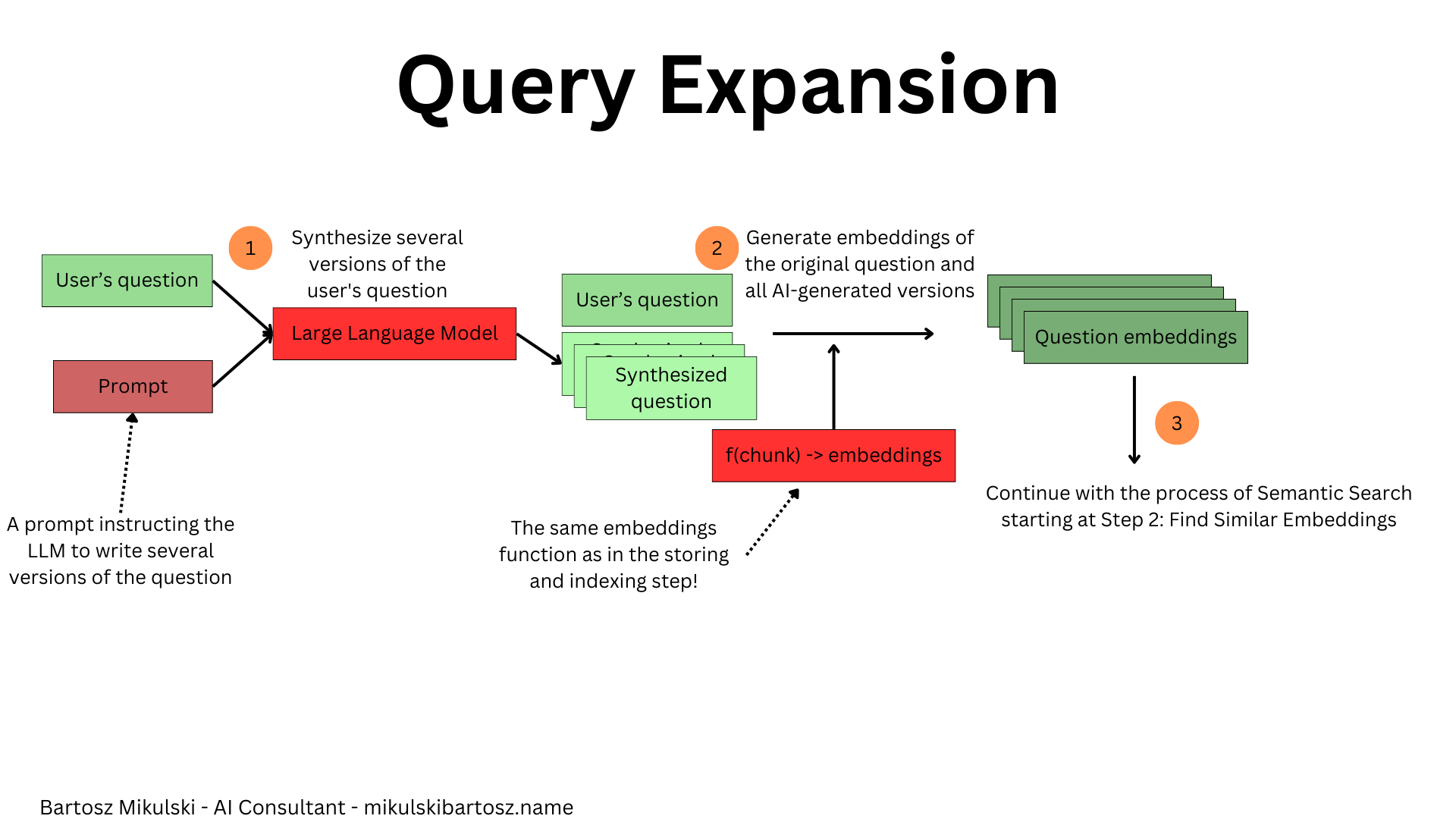
The answer quality depends on the similarity between the user’s question and the data in the database. If the user asks the same question using slightly different wording, they may get a different answer. It’s not ideal, but we can use it to our advantage.
Instead of retrieving only the documents similar to the user’s question, we can generate several versions of the question, calculate their embeddings, and retrieve document chunks for every version separately. In the end, we pass all of the retrieved documents (or only the most common documents, or most relevant documents according to a reranking algorithm I describe later) to the LLM and get the answer.
With query expansion, we don’t rely on the user’s ability to write a question and luck; instead, we increase the likelihood of returning a correct response by getting more similar documents from the database.
HyDE - Hypothetical Document Embeddings
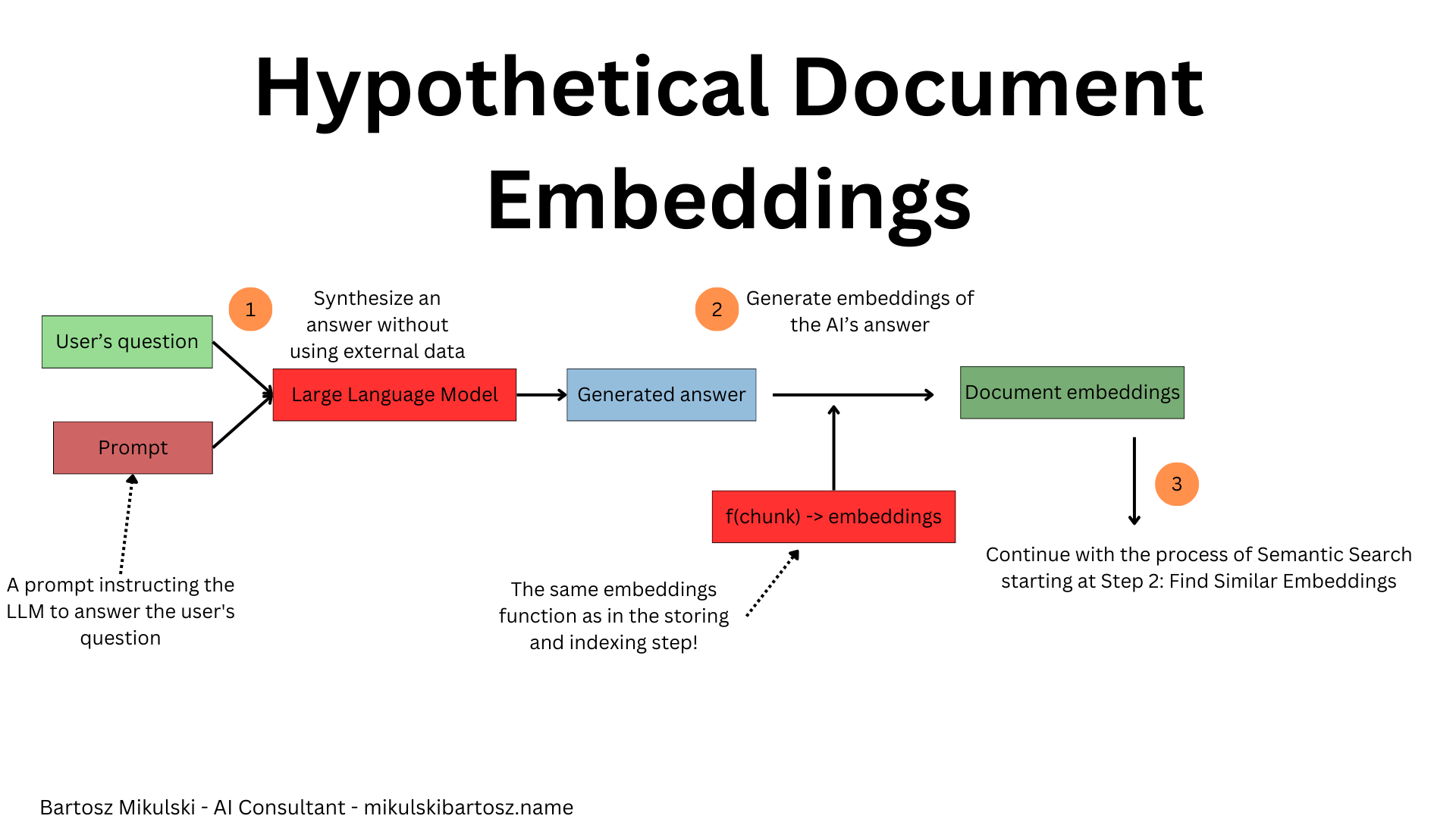
So far, we have used question embeddings to find similar document embeddings. Isn’t that weird? It may not be equivalent to comparing apples with oranges (after all, it sometimes works fine), but certainly, it’s like comparing tangerines with oranges. The authors of the “Precise Zero-Shot Dense Retrieval without Relevance Labels” paper also noticed the problem and proposed a solution called Hypothetical Document Embeddings (HyDE).
In the HyDE approach, we use a language model to generate an answer for the user’s question, calculate the embeddings of the generated answer, and use the embeddings to find relevant documents in the database. After that, we forget the generated answer and generate one using the actual documents.
The first answer generated by AI isn’t based on any documents, so it may contain hallucinations or be entirely wrong. It’s not a problem because the user will never see the generated answer. Instead, we hope the AI-generated document is similar to those containing the correct answer.
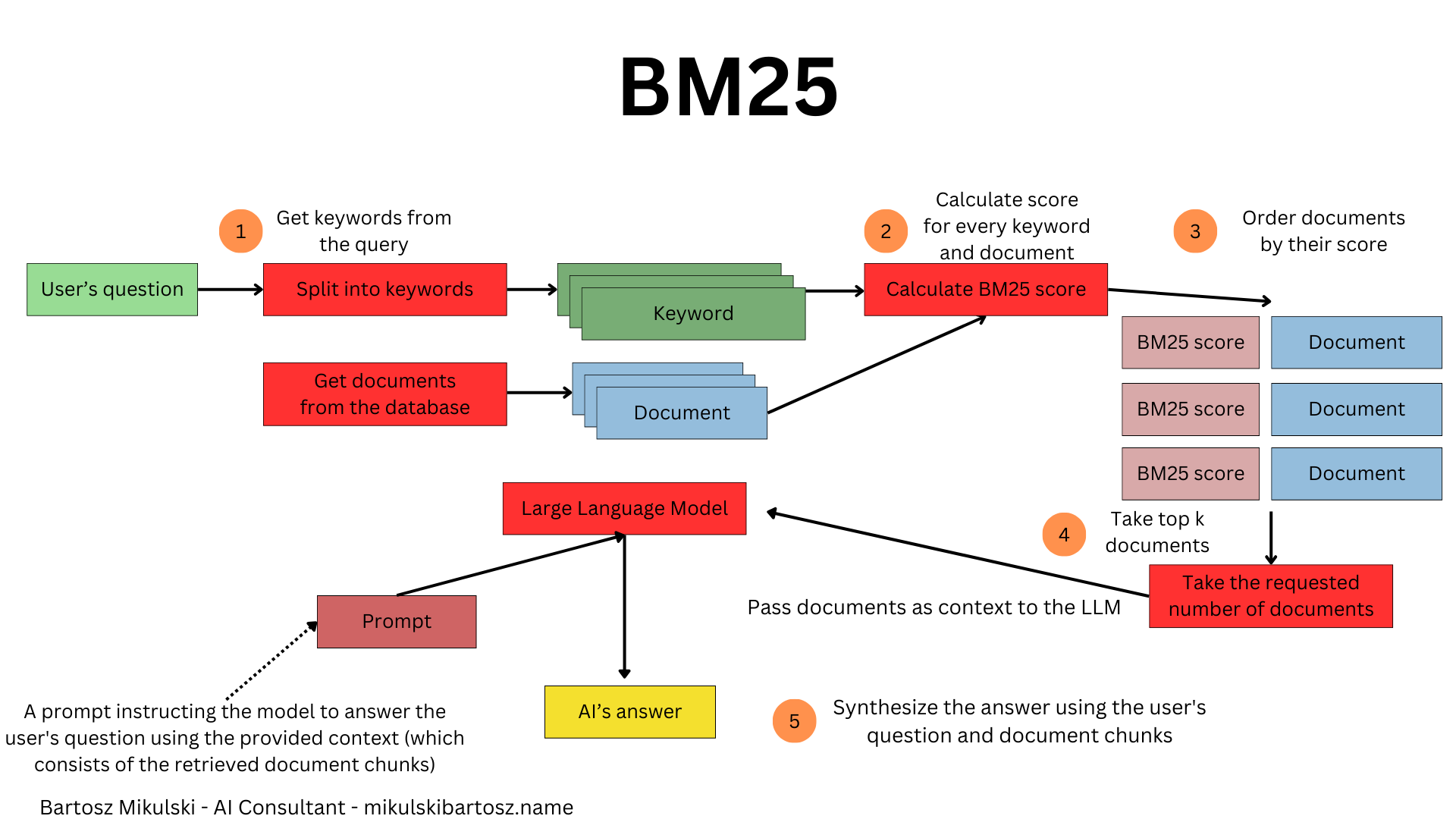
Keyword search - BM25
Instead of using embeddings, we can also try keyword search.
In this approach, we split the user’s question into words and treat every word as a keyword for the search. For every word, we iterate over the available documents and calculate Term Frequency (the frequency of the searched keyword in a given document), Inverse Document Frequency (a measure of how uncommon the keyword is among all documents. IDF helps us ignore common words), Document Length (the longer the document, the more often it may contain the keyword, so we want to penalize long documents), and Average Document Length (the average length of all documents. The BM25 algorithm uses it to normalize scores).
Finally, the algorithm orders the documents according to the calculated score and returns the requested number of documents (assuming that the database contains more documents than requested).
From the algorithm’s description, we see we don’t need embeddings. It’s uncommon for a vector database to support BM25 search. Some databases supporting semantic search and BM25 are Elasticsearch or Weaviate.
Self query - extracting metadata
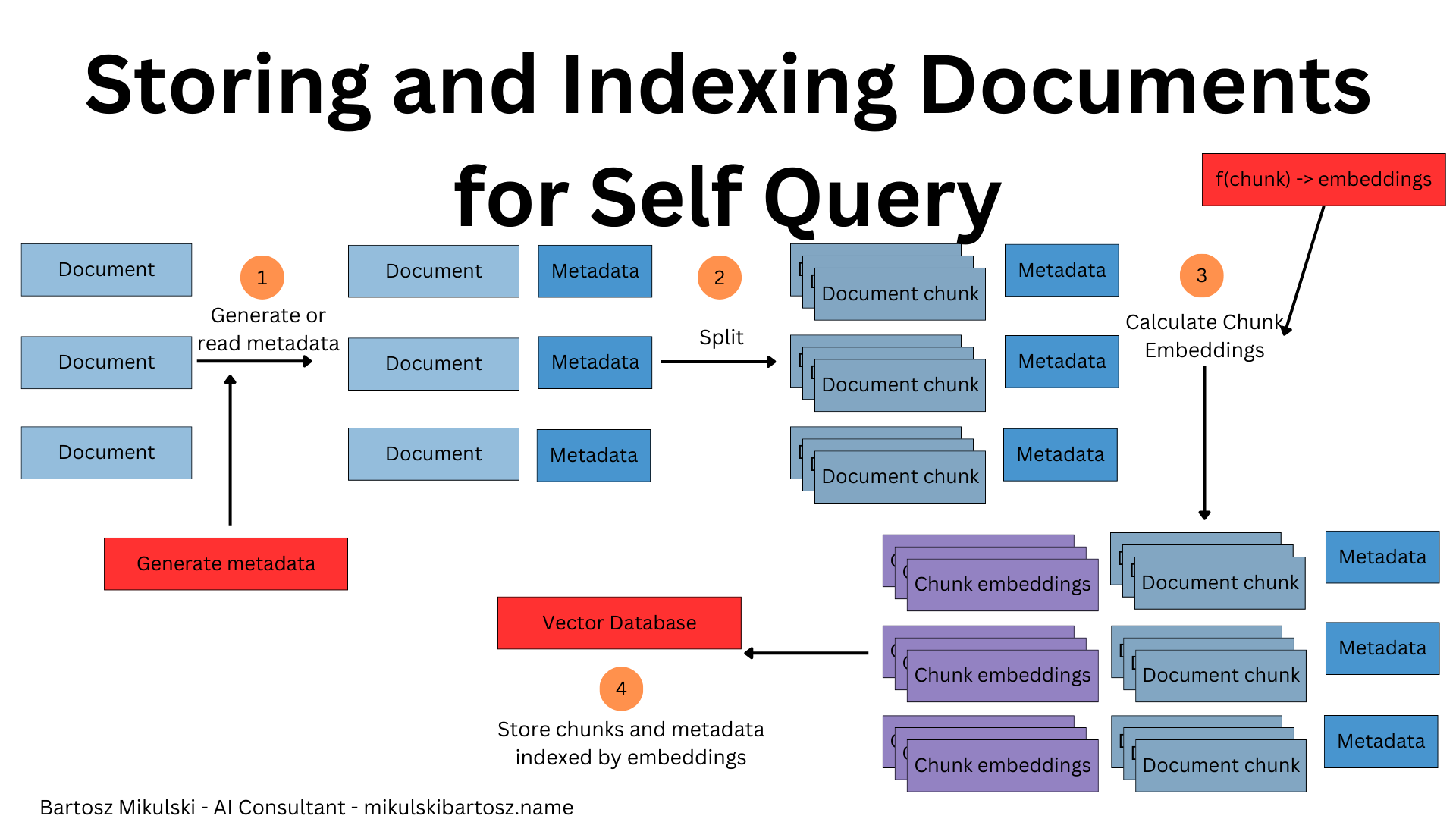
Text is not everything. Sometimes, the documents we process also have metadata describing their titles, creation date, authors, source from which it was downloaded, flags indicating whether the content is up-to-date or an archive version of the data, etc. We should be able to use the information while retrieving information with RAGs.
To do so, we must go back to the data ingestion step and store the relevant metadata with the documents and their embeddings. During ingestion, we must decide what metadata makes sense. If we make a mistake, we will have to backfill or update the documents later.
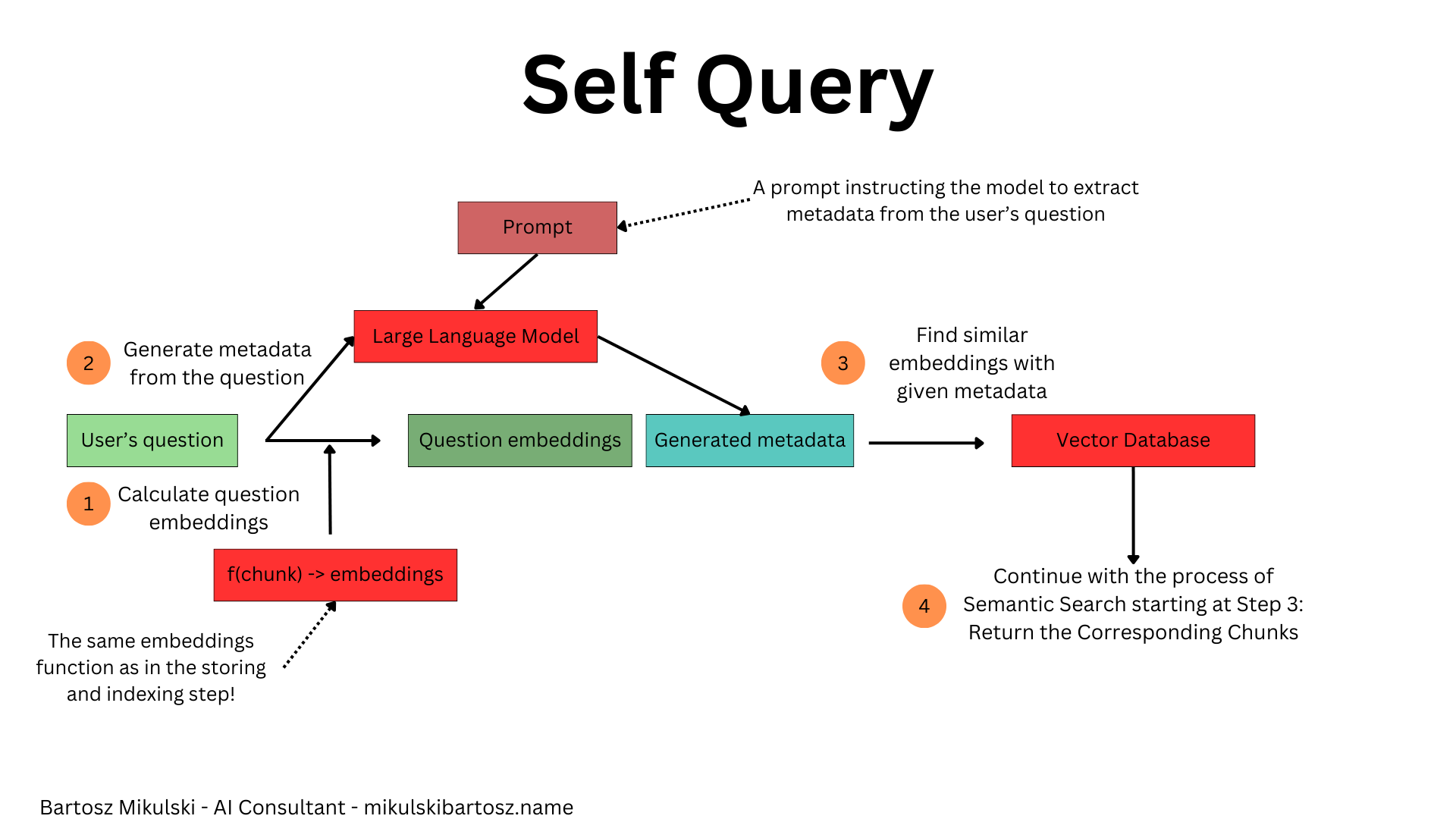
When the user asks a question, instead of passing the text directly to the vector database, we first use an LLM to extract metadata from the user’s query. Did they ask about a specific year or an author? Did they mention the name of a data source? Our prompt will need a description of all supported metadata types. When we get the response, we pass it together with the search vector to the vector database (or any other database; we can use metadata search with BM25 or even use the extracted metadata to build an SQL query).
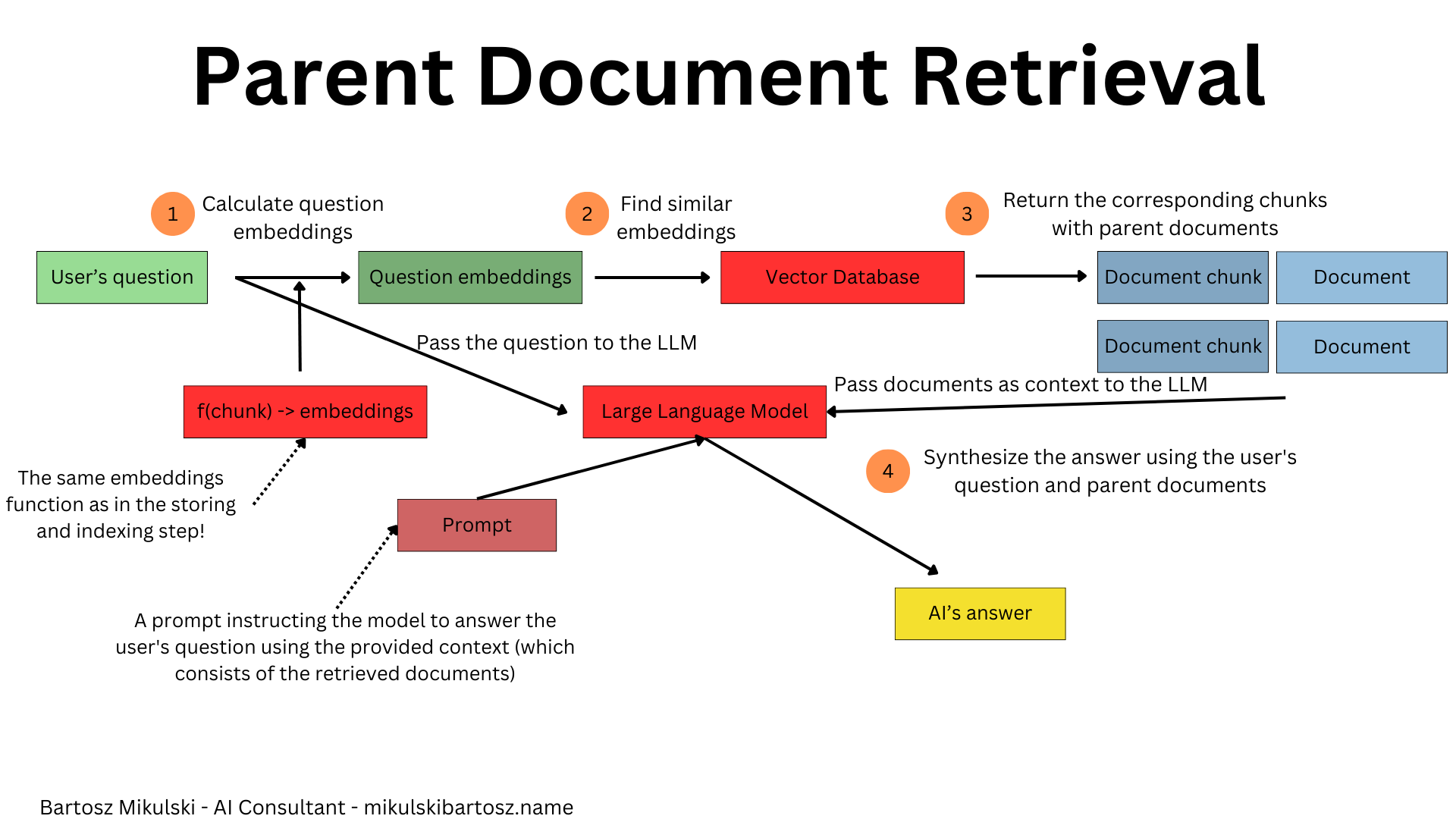
Parent Document Retrieval
When we store documents in the vector database, we split the documents into chunks. We split them because we hope the chunk will contain specific information answering a question with no irrelevant data and because we want to save tokens (so make the inference cheaper and faster). However, splitting documents may also cause some problems. For example, if we split a book chapter so that the introduction explaining the problem is in one chunk and the solution in another, our query may be more similar to the problem description than the solution, and RAG will never retrieve the solution from the database.
We can solve the issue by retrieving the matched chunk and the entire document containing the chunk. In this case, we have more data to help us answer the question, but as a tradeoff, we have to use more tokens (so pay more for using AI) and risk that the larger document will contain irrelevant information and confuse the language model.
However, we have to plan using the Parent Document Retrieval when we design the data ingestion because our database needs references from chunks to the parent document.
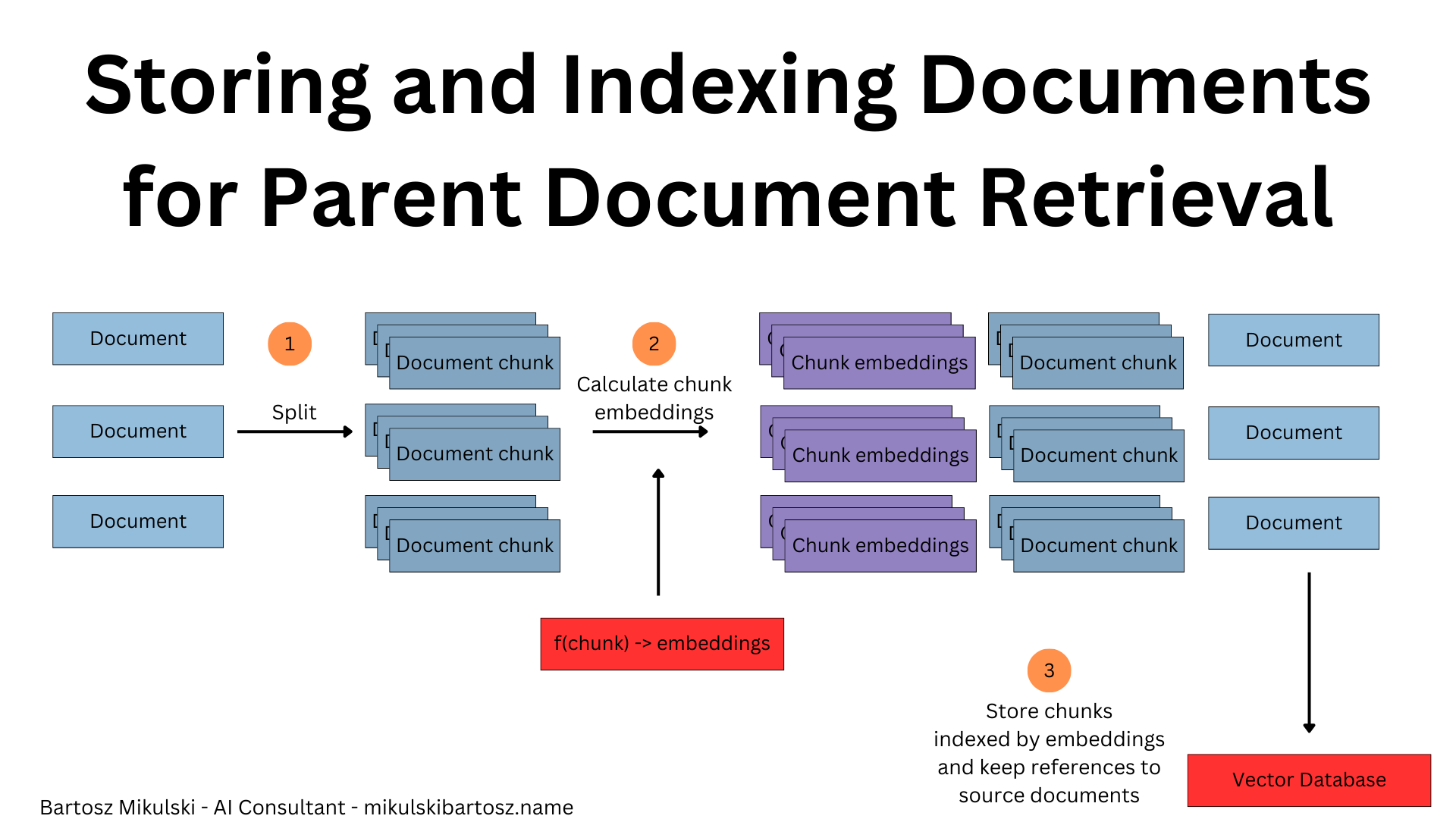
When we retrieve the data, search vectors match chunks, but we receive entire documents containing the matched chunks.
Reranking
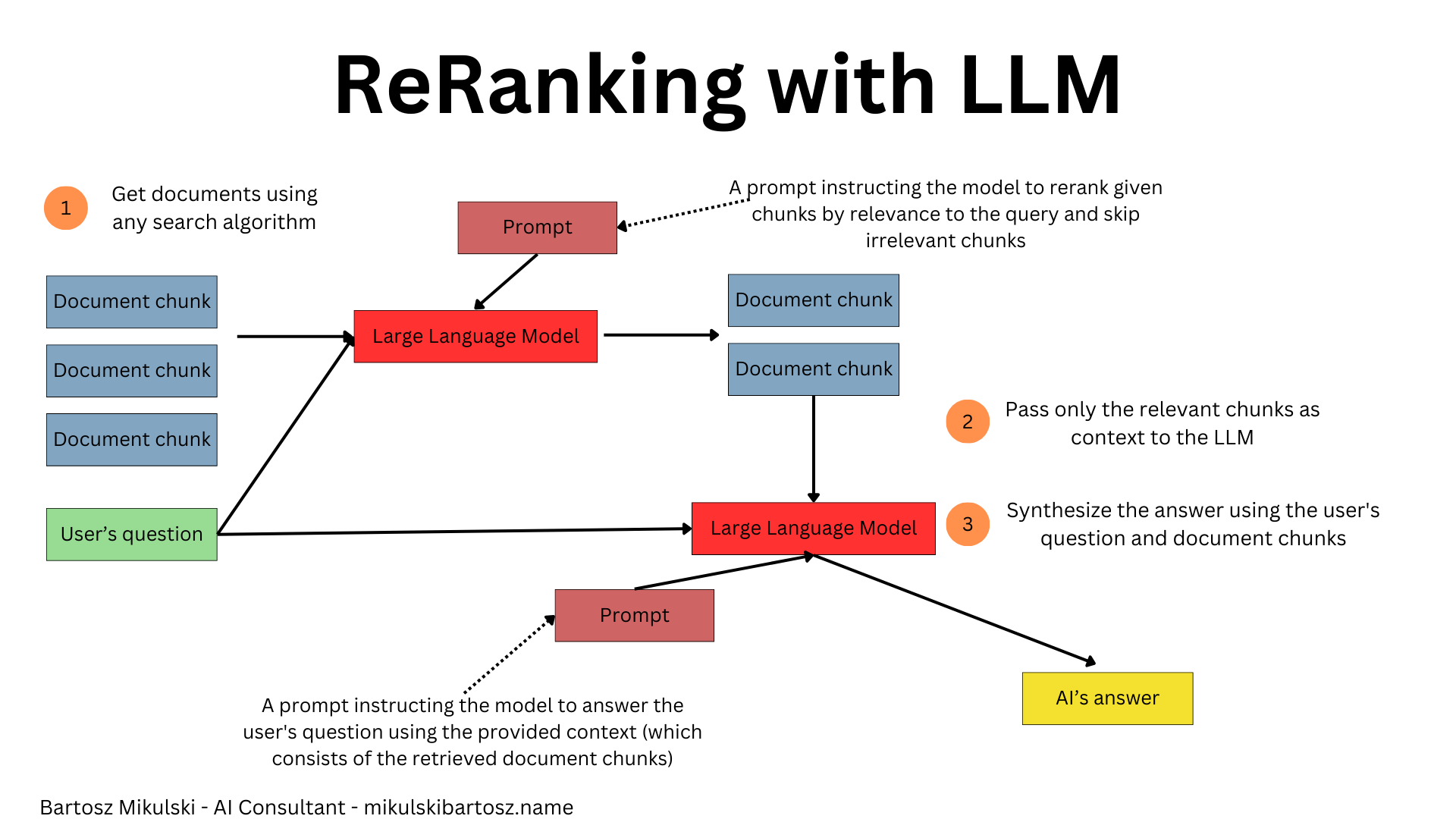
All of the aforementioned retrieval techniques can return multiple documents. In the case of query expansion, we may receive way more documents than we expect. In all cases, the documents should be ordered by their relevance, but the relevance is described as similarity to the query vector. The proper relevance order may differ when we consider the actual content of documents (or document chunks).
Reranking helps us limit the documents to only the most relevant ones or arrange them in the proper order if we instruct the AI to consider the order of chunks.
Technically, we have already used ranking algorithms. Every search technique ranks the documents from the most to the least relevant to the given query. Now, we want to change the order of already retrieved documents, hence the name—reranking.
We can use vector similarity to rerank documents retrieved with BM25 or BM25 to rerank documents from a semantic search. However, the most advanced reranking setup uses an LLM with a prompt instructing AI to order the chunks based on their relevance to the user’s query and filter out irrelevant chunks (or entire documents if you used parent document retrieval).
The problem with all retrieval algorithms
The retrieval and ranking algorithms listed here have one common problem: they always return something. If you want the three most similar documents from your database and the vectors of those documents happen to have a similarity of -0.7 while comparing them to the search vector, you will get those documents. Your RAG system will produce an answer even when the most similar documents aren’t really similar. In my previous article, I showed how to deal with the hallucination problem caused by irrelevant source data when using llama-index for RAG.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn