
We all have seen people building AI chatbots to talk with their notes, databases, books, PDFs, etc. What about a chat with a YouTube video? Or many videos at once? What about a chatbot using data from all videos in a channel? Let’s build one!
Table of Contents
- Retrieval Augmented Generation (RAG) with Llama Index
- Is it Legal to Build a Chatbot Using YouTube Videos?
- Code Dependencies
- Downloading Video Transcripts
- Preprocessing the Transcripts to Generate Questions and Answers
- Storing the Questions and Answers in the Vector Database
- AI Chatbot with Access to the Vector Database
- Building a UI for the AI Chatbot
- Running the Code
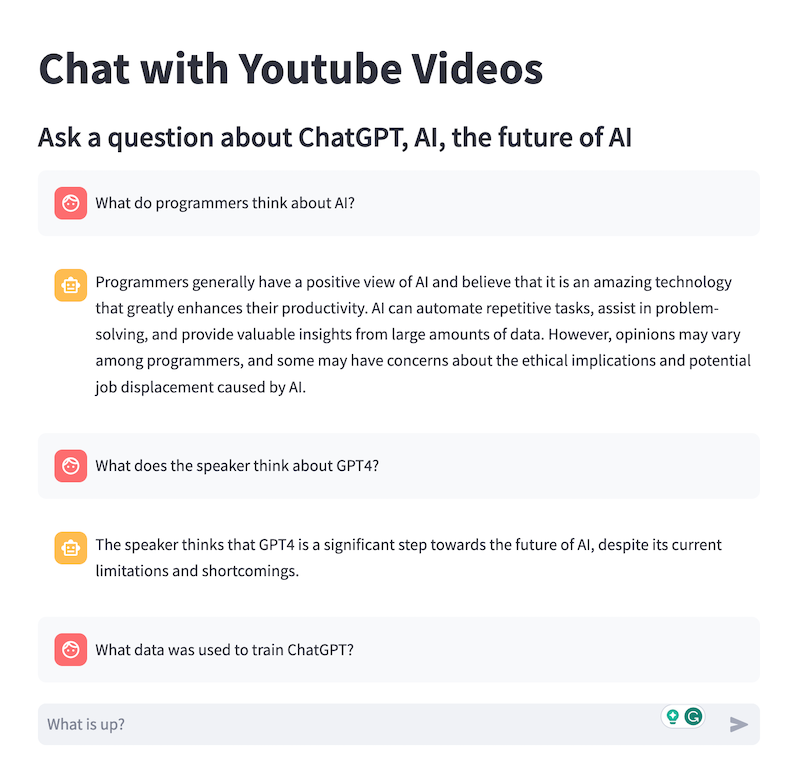
In the screenshot above, I have a chatbot answering questions using data extracted from transcripts of interviews in which the participants talk ChatGPT, AI, and speculate about the possible future of AI.
Retrieval Augmented Generation (RAG) with Llama Index
The code I wrote downloads transcripts, generates questions and answers, and stores those Q&A as separate documents in a vector database. When a user asks a question, AI retrieves relevant data from the database and generates the answer using the retrieved excerpt. That’s the RAG. The name of the answer-generating technique sounds way smarter and more complicated than the actual process. If you want to build a similar chatbot using the OpenAI Assistant API, check out my article on building a chatbot with a custom GPT assistant.
On top of the chatbot, I built a basic user interface using pre-defined chat components from the Streamlit library.
Is it Legal to Build a Chatbot Using YouTube Videos?
I would be shocked if anything would stop you from building and publishing an AI chatbot using the transcripts of your own videos.
However, it gets complicated when we want to use the content from someone else’s channel. Ask a lawyer or/and get permission from the channel’s owner first. Also, I believe you can build such a chatbot freely if you don’t share the service or the database with anyone else. If you are the only person who uses your software, what’s the difference between running a chatbot and downloading transcripts to read them? Again, to be sure, ask a lawyer.
Code Dependencies
I used the following libraries in my code:
[tool.poetry.dependencies]
python = ">3.9.7,<3.12"
llama-index = "==0.8.54"
openai = "==0.28.1"f
chromadb = "==0.4.15"
transformers = "==4.34.1"
torch = "==2.1.0"
python-dotenv = "==1.0.0"
streamlit = "==1.28.0"
youtube-transcript-api = "==0.6.1"
tqdm = "==4.66.1"
Downloading Video Transcripts
Before we start, we need a list of video IDs. A video ID is a URL part after the v= attribute name. For example, if our URL is https://www.youtube.com/watch?v=dQw4w9WgXcQ, its video id is dQw4w9WgXcQ. Getting the video IDs is out of the scope of this article. You can copy them from the browser’s address bar, use the YouTube API, or run a web scraper. Whatever you choose, I’m going to assume you have a variable containing a list of video IDs:
video_ids = ['dQw4w9WgXcQ']
Let’s download the transcripts using the youtube-transcript-api library:
from dataclasses import dataclass
from youtube_transcript_api import YouTubeTranscriptApi
from youtube_transcript_api._errors import CouldNotRetrieveTranscript
@dataclass
class Transcript:
video_id: str
text: str
def __get_transcript_from_video_id(video_id):
try:
transcript = YouTubeTranscriptApi.get_transcript(video_id)
return "\n".join([line["text"] for line in transcript])
except CouldNotRetrieveTranscript as e:
# I don't include logging in the article, but you should do it in your code.
#logger.warning(f"Could not retrieve transcript for video {video_id}: {e}")
return None
transcripts = []
for video_id in video_ids:
transcript = __get_transcript_from_video_id(video_id)
if transcript:
transcripts.append(Transcript(video_id, transcript))
Preprocessing the Transcripts to Generate Questions and Answers
Instead of putting the entire transcript into the vector database or cutting the transcript in random places to put chunks in the database, we extract the information relevant to the chatbot’s purpose. After all, we want to chat about a specific topic, not about greetings, introductions, off-topic discussions, or the video’s sponsor. Therefore, we generate Q&A about a pre-defined topic based on the video transcript.
Q&A Prompt
We could use Doctran to generate the Q&A. Unfortunately, Doctran would generate irrelevant questions because we can’t tell it what topic we are interested in.
Instead, we use the OpenAI API directly with our prompt:
QA_PROMPT_TEMPLATE = """Given a transcript of a YouTube video. Prepare a list of questions, answers, and quotes. Put every question, quote, and answer inside <qa> </qa> tags.
Include only topics that may be helpful when answering questions about {topic}. Don't include information about the next video, newsletters, gifts, products sold by the author, etc.
Format:
---
<qa>
Question: the question
Quote: A quote from the video that answers the question
Answer: A short answer
</qa>
---
"""
def __prepare_question_and_answer_extraction_prompt(topic_description: str) -> str:
return QA_PROMPT_TEMPLATE.format(topic=topic_description)
Q&A Generating Code
The following code makes Q&As from all of the available transcripts. The response class QuestionAndAnswer contains a method converting the data into a format used by Llama-index.
import re
import openai
from tqdm import tqdm
openai.api_key = ... # put your API key here
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index import Document
@dataclass
class QuestionAndAnswer:
video_id: str
content: str
def to_document(self) -> Document:
return Document(
text=self.content,
metadata={"video_id": self.video_id},
)
def get_questions_and_answers_from_transcripts(
transcripts: List[Transcript], topic_description: str
) -> List[QuestionAndAnswer]:
prompt = __prepare_question_and_answer_extraction_prompt(topic_description)
questions_and_answers = []
for transcript in tqdm(
transcripts, desc="Extracting questions and answers from transcripts"
):
questions_and_answers.extend(
__get_questions_and_answers_from_single_transcript(transcript, prompt)
)
return questions_and_answers
In the __get_questions_and_answers_from_single_transcript function, we split the transcript into chunks so they fit into the AI’s token limit, and we generate Q&A from each chunk separately. A single chunk may be a source of multiple questions.
def __get_questions_and_answers_from_single_transcript(
transcript: Transcript, prompt: str
) -> List[QuestionAndAnswer]:
chunks = __split_transcript(transcript)
questions_and_answers = []
for chunk in tqdm(chunks, desc="Extracting questions and answers from chunks"):
QAs = __extract_questions_and_answers(chunk, prompt)
for qa in QAs:
questions_and_answers.append(QuestionAndAnswer(transcript.video_id, qa))
return questions_and_answers
def __extract_questions_and_answers(chunk_content: str, prompt: str) -> List[str]:
final_result = []
messages = [
{"role": "system", "content": prompt},
{"role": "user", "content": chunk_content},
]
chat_completion = openai.ChatCompletion.create(
model="gpt-3.5-turbo", max_tokens=1000, messages=messages, temperature=0.0
)
response = chat_completion["choices"][0]["message"]["content"]
pattern = r"<qa>(.*?)<\/qa>"
qa_blocks = re.findall(pattern, response, re.DOTALL)
final_result.extend(qa_blocks)
return final_result
Let’s call the function we have created and get Q&A from the video transcript while keeping the questions focused on the topic we choose:
topic = "ChatGPT, AI, the future of AI"
QAs = get_questions_and_answers_from_transcripts(transcripts, topic)
Storing the Questions and Answers in the Vector Database
We must implement a class encapsulating all database operations and create a QueryEngineTool with the database used as the backing storage:
from typing import List
import chromadb
from llama_index import VectorStoreIndex, ServiceContext
from llama_index.vector_stores import ChromaVectorStore
from llama_index.storage.storage_context import StorageContext
from llama_index.tools import QueryEngineTool, ToolMetadata
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.storage.storage_context import StorageContext
from .transcripts import QuestionAndAnswer # !!!CHANGE `.transcripts` TO THE MODULE WITH THE `QuestionAndAnswer` CLASS!!!
In the constructor, we create a Chroma vector database stored in the local file system. Additionally, we download an embeddings model from HuggingFace. In this case, we use BAAI/bge-base-en-v1.5 because of the model’s size. The model is small enough to download fast and fit in memory.
class Database:
def __init__(self, database_path: str, topic: str):
self.topic = topic
db = chromadb.PersistentClient(path=database_path)
chroma_collection = db.get_or_create_collection("videos")
self.vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
self.storage_context = StorageContext.from_defaults(
vector_store=self.vector_store
)
self.service_context = ServiceContext.from_defaults(embed_model=embed_model)
To insert data into the database, we implement an insert function, creating a VectorStoreIndex from the given documents:
# This is a continuation of the previous code snippet
# put it inside the Database class
def insert(self, questions_and_answers: List[QuestionAndAnswer]):
QAs = [qa.to_document() for qa in questions_and_answers]
VectorStoreIndex.from_documents(
QAs,
storage_context=self.storage_context,
service_context=self.service_context,
)
The code we have prepared so far is enough to store the data. Remember, we will add another function to the Database class later. For now, let’s create a database and insert the data:
database_path = "chroma_db"
database = Database(database_path, topic)
database.insert(QAs)
AI Chatbot with Access to the Vector Database
Finally, we can start building the chatbot. Before we begin, let’s add the missing function to the Database class. In the function, we instantiate a VectorstoreIndex using the data stored on the disc and create a QueryEngineTool. The tool allows AI to call our database and retrieve any information AI needs. In the tool description, we must inform AI what it does and when to use it.
# This is a continuation of the Database class !!!
def to_qa_tool(self, tool_name: str) -> QueryEngineTool:
index = VectorStoreIndex.from_vector_store(
self.vector_store,
service_context=self.service_context,
)
video_query_engine_tool = QueryEngineTool(
query_engine=index.as_query_engine(),
metadata=ToolMetadata(
name=tool_name,
description=f"useful for when you want to answer questions about {self.topic}",
),
)
return video_query_engine_tool
In the Chatbot class, we instantiate an OpenAIAgent and configure the agent with the database access tool. Additionally, we instruct AI to always use the tool before answering a question. Otherwise, AI could answer user’s questions using only information the model learned while training.
from .database import Database
from llama_index.agent import OpenAIAgent
class Chatbot:
def __init__(self, database: Database, verbose: bool = False):
self.tool_name = "database"
tool = database.to_qa_tool(self.tool_name)
self.prompt_template = f"Use the tool: {self.tool_name} to answer the question. Question: "
self.agent = OpenAIAgent.from_tools([tool], verbose=verbose)
def ask(self, question: str) -> str:
prompt = self.prompt_template.format(question=question)
answer = self.agent.chat(prompt)
return answer.response
The History of a Conversation
The implementation above doesn’t preserve the chat history. We display all messages, but AI gets only the most recent message.
A better approach would be to store the messages somewhere between interactions with the user and pass them to AI in the chat_history parameter. Because Streamlit stores messages as dictionaries in the session state, we can use the session state as our chat history storage.
Let’s define an additional method to pass the chat history to the AI model:
from llama_index.llms.base import ChatMessage, MessageRole
# Put the following methods inside the Chatbot class
def ask_with_history(self, question: str, history: List[Dict]) -> str:
prompt = self.prompt_template.format(question=question)
chat_history = self.__convert_history(history)
answer = self.agent.chat(prompt, chat_history=chat_history)
return answer.response
def __convert_history(self, history: List[Dict]) -> List[ChatMessage]:
return [
ChatMessage(
content=msg["content"],
role=MessageRole(msg["role"])
)
for msg in history if msg["content"] is not None
]
Building a UI for the AI Chatbot
Finally, we build the web UI. We must import the Streamlit library and two classes we defined earlier. In the code snipped below, I assume that both are defined in separate files inside the chatbot module:
import streamlit as st
from chatbot.database import Database
from chatbot.chat import Chatbot
# use the database_path and topic defined earlier
database = Database(database_path, topic)
chatbot = Chatbot(database)
The UI displays the chatbot window and a prompt where users can type questions. When we receive a new request, we copy the existing messages from the session state, update the chatbot’s web interface, and call OpenAI API. After receiving the answer, we update the chat’s UI and modify the session state.
st.title("Chat with Youtube Videos")
st.subheader(f"Ask a question about {topic}")
if "messages" not in st.session_state:
st.session_state.messages = []
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
if prompt := st.chat_input("What is up?"):
chat_history = list(st.session_state.messages)
with st.chat_message("user"):
st.markdown(prompt)
st.session_state.messages.append({"role": "user", "content": prompt})
answer = chatbot.ask_with_history(prompt, chat_history)
with st.chat_message("assistant"):
st.markdown(answer)
st.session_state.messages.append({"role": "assistant", "content": answer})
Running the Code
Before starting the web server, we must execute the data preparation code. If you put the code in the preprocessing.py file, preprocessing may require running the following command: poetry run python preprocessing.py. The poetry run part is necessary because we use the Poetry package manager to manage our dependencies (as defined in the “Code Dependencies” section).
To run the web application, we must call streamlit run your_file_with_streamlit_code.py.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn