
The Kappa Architecture is a data engineering architecture used to process event streams. Kappa Architecture allows programmers to use a single technology stack where two separate stacks were previously needed for real-time and batch processing. It is an implementation of streaming architecture. As such, it is based on the idea of permanently storing a series of incoming data (events) and using a stream processing engine to transform data and calculate aggregations.
Table of Contents
- How does Kappa Architecture look?
- Is Kappa Architecture better than Lambda Architecture?
- How can we produce a materialized value of a stream?
- What problems does Kappa Architecture Solve?
- What problems does Kappa Architecture cause?
- Conclusion
The aggregates produced by the stream processing engine are sent to yet another stream. Finally, we can consume the events from an aggregated stream or build a materialized table containing the always-up-to-date results.
How does Kappa Architecture look?
Kappa Architecture is an implementation of event stream processing. Because of that, the first thing we need is a stream of events.
Initially, it will be an empty stream, but we need to define it somewhere. Therefore, we need a stream processing engine (also known as a stream processing platform). We have tons of options. The most popular choices are Kafka, AWS Kinesis, and Redpanda.
Choosing a stream processing engine is a crucial decision. Technically, we can migrate between the engines, but we need to copy all events from one engine to another (that’s the easy part) and rewrite all stream processing code (that’s the hard part). It would require a code rewrite because all stream processing engines use similar yet slightly different language to define stream operations.
When we have a stream, we can start sending the events. Anything can produce events.
We can write a backend application and insert them into the stream explicitly. We can setup change data capture in a relational database and produce an event every time a row gets updated. Similarly, we could get a stream of events by subscribing to Put operations in an S3 bucket.
It would be great to use the event for something. Now, we must define a stream transformation in the stream processing engine. Generally, in the event transformation code, we can map the values to a different format, aggregate a subseries of events by a common value (for example, a time window), or join values from two streams.
Those operations produce another stream as a result, but we can also aggregate values into a materialized view which works like a table in a relational database. We can access such materialized views from external applications, join streams with values from the view, or produce another stream with events created when the view gets updated.
Finally, we need to consume the events. Here we have only two options. We can retrieve raw events from any stream or query the materialized views.
An example architecture using all of the elements mentioned above could look like this:
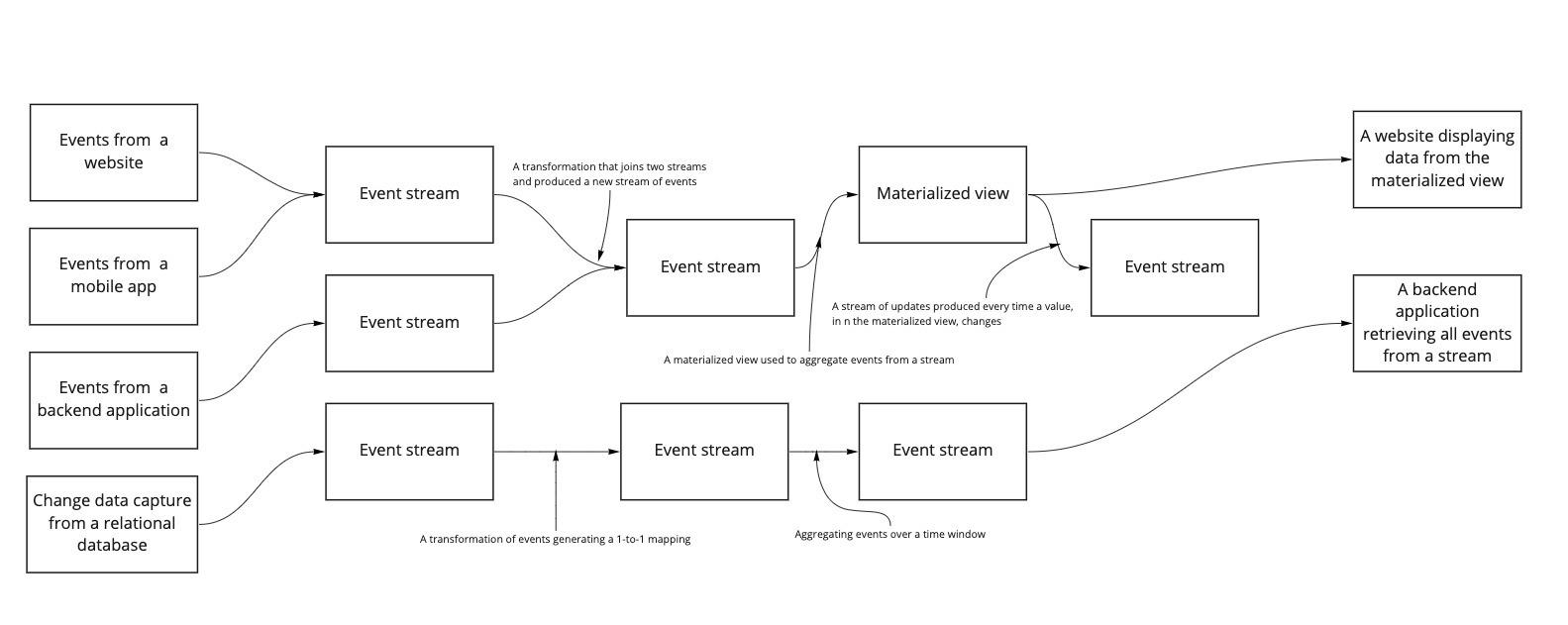
In the example above, we see four different kinds of event producers, the raw input streams to which the event producers write the data, streams with events derived from the input data, and a materialized view.
However, the essential part is the thing we don’t see. There is no batch processing unit to aggregate historical values. That’s the main difference between Lambda and Kappa architectures.
In the next section, I will show why removing batch processing from event streaming was a significant change in data engineering.
Is Kappa Architecture better than Lambda Architecture?
Lambda Architecture has one big problem, which was pointed out by Jay Kreps. When we design a Lambda-Architecture-based system, we have to implement the same behavior twice - once in the stream processing code and once for the batch processing.
We double the work by implementing the same operations in two different ways. We can’t copy-paste the code because streaming is significantly different than batch. The doubled effort isn’t the only problem.
We have trouble keeping both versions in sync when we have code duplication, especially when the code is conceptually the same but implemented differently. If we don’t, the stream processing will produce different results than batch. Over time, we would accumulate errors.
Theoretically, we could generate code for both implementations from a common language or create the batch version from the streaming code. After all, in the stream system, we can use KSQL to define the stream transformations. Similarly, we could use Spark SQL to define the batch code.
Both SQL dialects don’t differ much. However, those differences make creating a translation layer between both implementations a tedious task. Also, we may pretend that Spark SQL hides the implementation details. In reality, you better remember about data partitioning and shuffling. Otherwise, the solution would perform poorly.
In Kappa Architecture, we don’t have the batch processing part for aggregating historical data. We do everything in streams using the same code all the time. There is no additional effort.
Of course, thinking in streams doesn’t come naturally to programmers. Implementing Kappa Architecture requires lots of experience in stream processing and distributed systems.
In the case of Lambda Architecture, you could decide that not all operations are supported in streams, and some data is available later after running a batch job. It was handy when the problem was getting too difficult for the team to handle, and the programmers preferred taking an easier approach.
How can we produce a materialized value of a stream?
Because of stream-table duality creating a materialized view of a stream isn’t a big deal. How come?
When we have a table in a relational database, we could build a stream of SQL statements changing the data in the table. It would be a stream of INSERT, UPDATE, and DELETE operations. We could send a stream of those operations to a different application. In the other application, we could run the received queries on another database. After doing that, we would get the same data in both databases.
How do we know it works? A transaction log in relational databases works like this. It can repeat the operations to get the final result in a table. Database replication works similarly to a transaction log. It sends data changes as messages to database replicas. Finally, Change Data Capture is based on the same idea - send the SQL operation as a message to get a copy of the data. We do it all the time.
In stream processing engines, we apply a stream of operations to a materialized view. It recalculates its values every time a new event arrives. Fine. Most likely, it uses micro-batches and recalculates periodically. But that’s just a performance optimization. Conceptually, it recalculates after receiving every message.
Similarly, we could take snapshots of a table from two different dates and produce a series of operations that would transform the earlier snapshot into the other. We could figure out all the inserts, updates, and deletions we must make.
Because of that, tables and streams are interchangeable. We can produce a table from a stream of events and generate events every time a table changes. Consequently, we can define materialized views that provide an interface for the data consumers or work as a cache inside the stream processing engine.
What problems does Kappa Architecture Solve?
As mentioned earlier, when we switch to Kappa Architecture from Lambda Architecture, we no longer need to maintain two versions of the same code - one for streams and one for batch.
The developers don’t have to learn two different frameworks, work with two different data processing technologies, and the data access layer in producer and consumer applications uses one interface.
That’s probably the only problem solved by choosing Kappa instead of Lambda Architecture. Don’t get me wrong. It’s only one problem, but it’s a huge painful problem that annoys you daily.
If you remember that every mistake in data processing eradicates trust in the data team, choosing an architecture that reduces the possibility of error looks like a good idea.
What problems does Kappa Architecture cause?
Every time you modify the code, all events in the modified stream and all the downstream streams must be recalculated. It’s not a cheap operation, and it isn’t automated. You can easily create a new version of the data processing code and get a new stream, but you will need to create new versions of all the streams that depend on the newly created one.
As far as I know, no stream processing engine automates the process. It would be cool to write one ALTER STREAM statement, modify the underlying select statement in any way we want, and get the downstream data recalculated. Instead, we must create a new version of the code we want to change, new versions of downstream streams, stop using the old versions, and remove them.
Of course, the same problem exists in the stream part of Lambda Architecture, but there we can decide that the recalculated values come from batch, and we don’t care about propagating the change in a stream.
Conclusion
Event stream processing is complex no matter what architecture you choose. Choosing the right one won’t magically solve all of your problems. Also, which one is the right one?
I suggest starting with Kappa Architecture because you need streams anyway. Later, you will decide whether batch backfill makes sense. Although, don’t switch to batch just because it’s easier than getting the same results in a stream. That’s the wrong reason to choose Lambda over Kappa.