
Are prompts code or configuration? If prompts are code, why can a change in an external system (the LLM API) break your application? If they are a configuration, why don’t you also put all SQL queries or names of the JSON fields extracted from a third-party API in the configuration? The problem with prompts is that they are kind of both. So, we may not want to manage them as code. That’s why Langfuse and other prompt management tools exist. If you need a refresher on writing effective prompts, check out my guide to prompt engineering.
Table of Contents
- What can we do with Langfuse?
- How to configure the Langfuse Python client
- How to configure the prompt
- How to use the prompt in the application
- How to track the LLM requests
- Adding metadata to the tracking information
What can we do with Langfuse?
In Langfuse, we can configure and version prompts. In the application, when we want to access an LLM, we first retrieve the current version of the prompt from Langfuse, fill out the variable placeholders, and then call the LLM API. The configuration may include the LLM endpoint, model name, temperature, and other parameters.
Because the configuration is stored in a separate system, we can change the prompt and the LLM configuration without redeploying the application. If we make a mistake, we can roll back to the previous version. We can also easily compare different versions of the prompt.
In addition to being a fancy git repository for prompts, Langfuse can track LLM requests. We can store the inputs, LLM’s output, metadata about the user, and other custom information. Of course, the version of the prompt used for a given request is also recorded.
How to configure the Langfuse Python client
I will use the OpenAI API, but Langfuse supports other LLM providers. I will use the cloud version of Langfuse, but it also works as a self-hosted application.
After installing the libraries, the first thing to do is configure the client using environment variables. We have to set the langfuse keys, the server URL, and the OpenAI API key.
import os
os.environ['LANGFUSE_SECRET_KEY'] = "sk-lf-..."
os.environ['LANGFUSE_PUBLIC_KEY'] = "pk-lf-..."
os.environ['LANGFUSE_HOST'] = "https://cloud.langfuse.com"
os.environ['OPENAI_API_KEY'] = "sk-proj-..."
Now, we import the Langfuse clients and initialize them:
from langfuse import Langfuse
from langfuse.openai import OpenAI
from langfuse.decorators import langfuse_context, observe
langfuse = Langfuse()
openai_client = OpenAI()
How to configure the prompt
In the Langfuse UI, we navigate to the Prompts page and click the New Prompt button. In the form, we can choose to have a text or chat-based prompt. Every message in the prompt can use placeholder variables (in double curly braces). We can also include a config dictionary intended to store the LLM parameters.
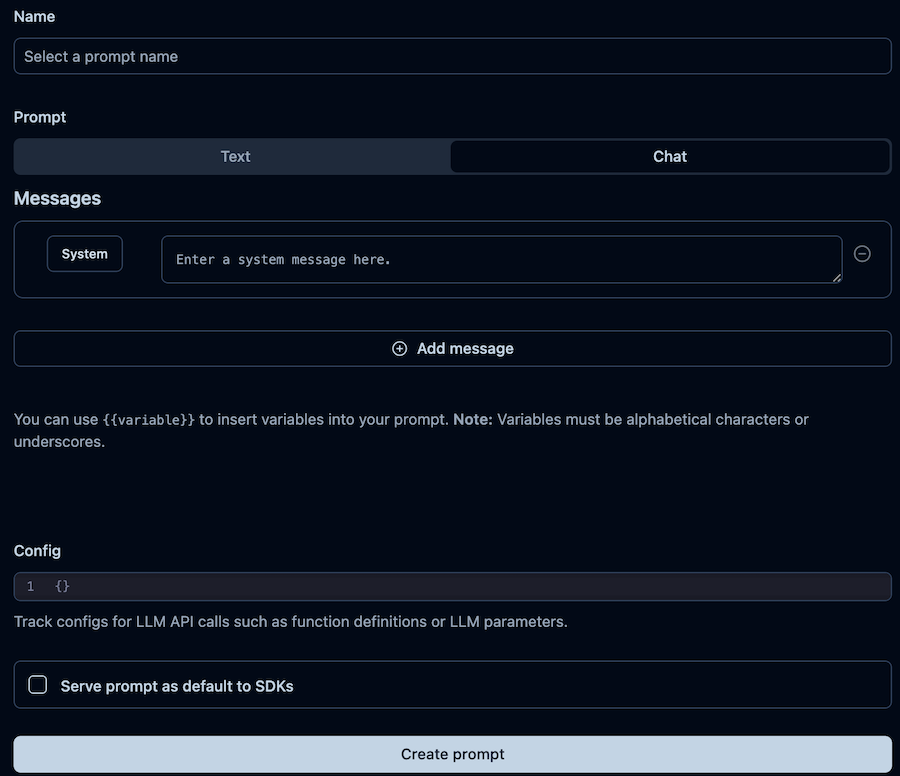
Remember to prompt the prompt to production after saving it! Otherwise, the Python client won’t find it while looking for the production prompt.
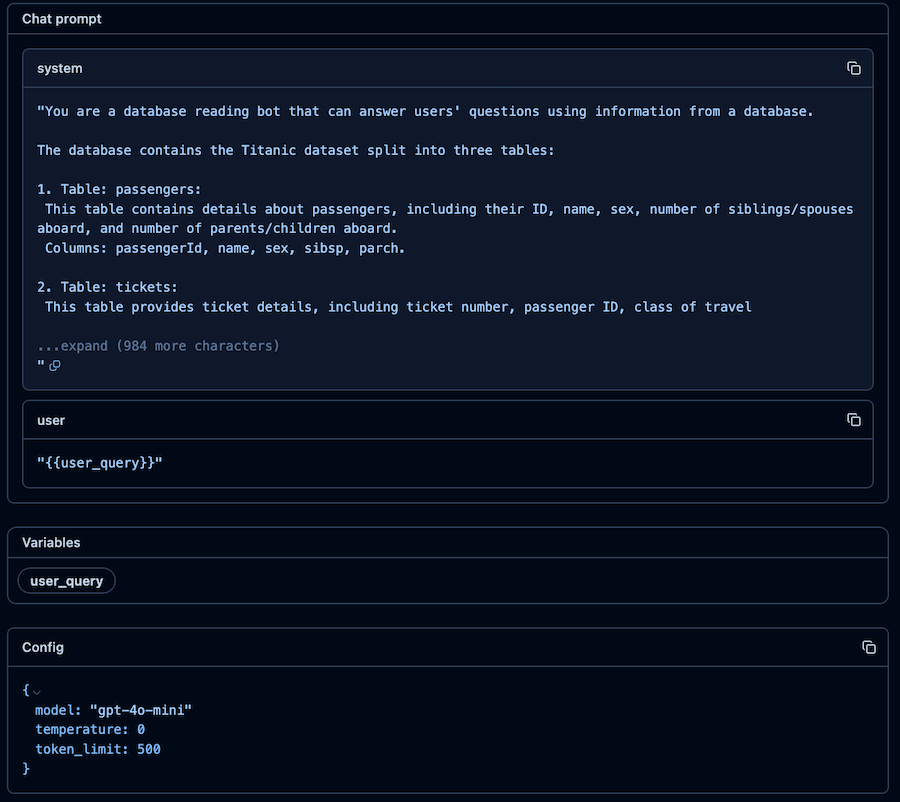
My example prompt produces a query execution plan for a given question. The answer is based on a database schema provided in the prompt. I expect to get the reasoning (an explanation of how to get the data from the database or why it’s impossible) and the can_answer flag (an indicator of whether the question can be answered based on the provided schema). The user’s question is passed as a variable user_query.
In the configuration, I selected the OpenAI model version, its temperature parameter, and the maximum number of tokens in the response.
How to use the prompt in the application
In Python code, we have to retrieve the current version of the prompt from Langfuse, compile the final version by providing the values for the variables, and then call the LLM API using the configuration from the prompt.
We use the Langfuse client for the OpenAI API, not the standard one! Also, I want structured output, so I provided a Pydantic model and passed the class as the response_format parameter.
from pydantic import BaseModel
class CanAnswerQuery(BaseModel):
reasoning: str
can_answer: bool
prompt = langfuse.get_prompt("parse_to_sql")
compiled_prompt = prompt.compile(user_query="How many French people were on board of the ship?")
prompt_config = prompt.config
res = openai_client.beta.chat.completions.parse(
model = prompt_config["model"],
temperature = prompt_config["temperature"],
messages = compiled_prompt,
max_tokens = prompt_config["token_limit"],
response_format=CanAnswerQuery,
)
res.choices[0].message.parsed
#CanAnswerQuery(reasoning="I can't answer how many French people were on board because the database does not contain information about the nationality of the passengers.", can_answer=False)
How to track the LLM requests
The code above is sufficient if we use Langfuse only for prompt management and basic tracking. (It will also automatically log the request in Langfuse!) However, we can have some control over the logged data and add more context to the request.
Why would we want to track the requests? We may wish to use the gathered data for debugging, cost monitoring, or training a custom model.
To track the requests, we must create a request context by including the code inside a function decorated with @observe decorator. With the decorator, Langfuse will log the interaction with the function and all LLM interactions inside of the function. We get a tree of trace data where the outer element is our function and inner values are individual LLM calls.
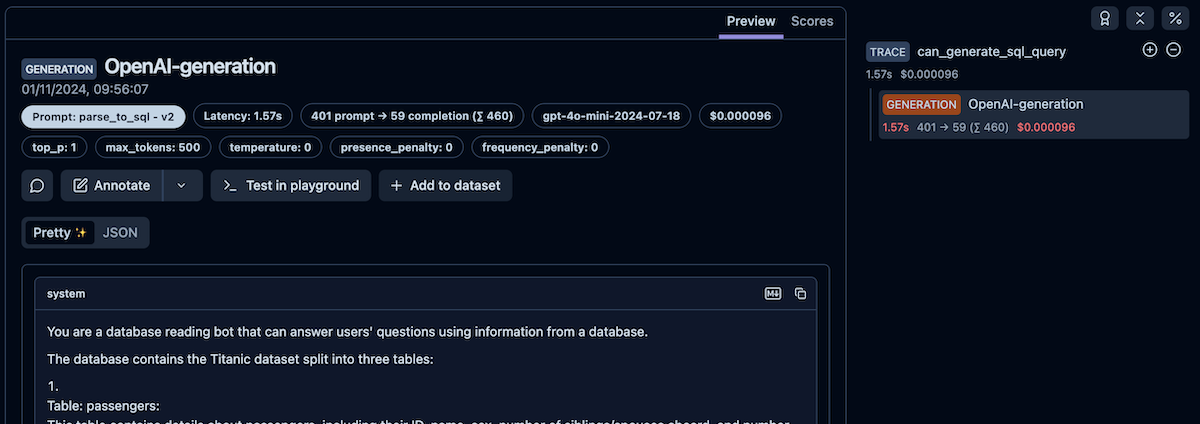
In the example below, I created a can_generate_sql_query function that uses the parse_to_sql prompt. In the parse function, I passed the prompt as the langfuse_prompt parameter, so its version will be tracked, too.
@observe
def can_generate_sql_query(user_query) -> CanAnswerQuery:
prompt = langfuse.get_prompt("parse_to_sql")
compiled_prompt = prompt.compile(user_query=user_query)
prompt_config = prompt.config
res = openai_client.beta.chat.completions.parse(
model = prompt_config["model"],
temperature = prompt_config["temperature"],
messages = compiled_prompt,
max_tokens = prompt_config["token_limit"],
langfuse_prompt = prompt,
response_format=CanAnswerQuery,
)
return res.choices[0].message.parsed
Adding metadata to the tracking information
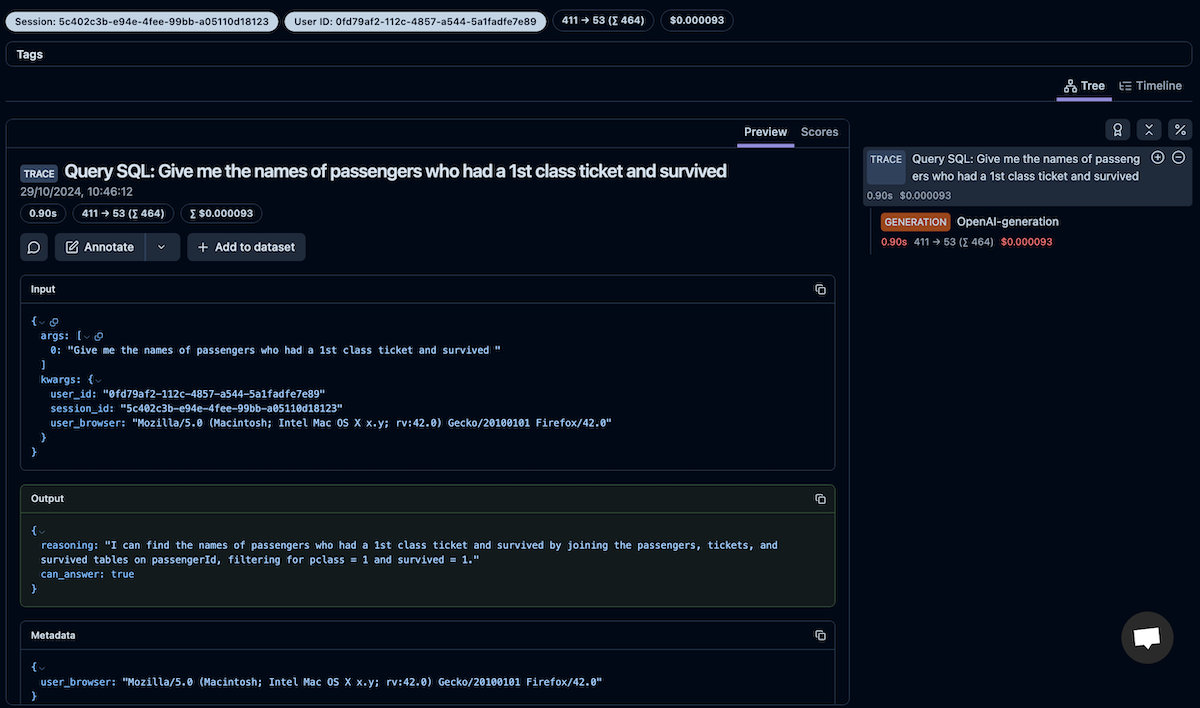
Often, we want to track who sent the request, the session ID, and perhaps other metadata. Inside a function decorated with @observe, we can access the langfuse_context object, which has the update_current_trace method. The function allows us to add the metadata to the trace. It has separate parameters for the user and session ID, but we can also log any dictionary as the metadata.
@observe
def can_generate_sql_query(user_query, *, user_id, session_id, **user_metadata) -> CanAnswerQuery:
compiled_prompt = prompt.compile(user_query=user_query)
res = openai_client.beta.chat.completions.parse(
model = prompt_config["model"],
temperature = prompt_config["temperature"],
messages = compiled_prompt,
max_tokens = prompt_config["token_limit"],
langfuse_prompt = prompt,
response_format=CanAnswerQuery,
)
langfuse_context.update_current_trace(
name=f"Query SQL: {user_query}",
session_id=str(session_id),
user_id=str(user_id),
metadata=user_metadata
)
return res.choices[0].message.parsed
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn