
I used to think embedding speed was just background noise. A few milliseconds here, a few milliseconds there, who really cares? But then I swapped out float vectors for binary ones and watched my search times shrink like a t-shirt in a hot dryer. Suddenly, those “insignificant milliseconds” started to matter.
Table of Contents
On paper, the embeddings model doesn’t look like a huge bottleneck in RAG: text-to-embedding takes a few milliseconds, OpenAI’s API round trip is under 100ms, and the search itself clocks in at about 10ms. Speed isn’t a problem… until it becomes one. And you’re staring down the need to squeeze every last drop of latency from your stack. That’s where binary embeddings come in.
In this article, I’ll show you how using binary vectors can supercharge your vector search, which distance metrics actually make sense, and how the embeddings affect the retrieval accuracy.
Binary embeddings in RAG
Binary embeddings are vectors of 0s and 1s. Think of swapping a shelf full of heavy hardcover books (floats) for a stack of postcards (binaries): lighter, faster to move, and taking up almost no space, though they don’t hold as much detail. Because they’re much smaller than floating-point vectors, binary embeddings are quicker to store and compute with, especially when paired with the right index type and distance metric.
I ran four different experiments to see how search speed changed with different vector setups:
- OpenAI baseline: Float vectors (1536 dimensions) from the OpenAI Embeddings API, stored in an IVF_FLAT index with cosine distance.
- Open-source float: Float vectors (1024 dimensions) from the BAAI/bge-large-en-v1.5 model, same index type and distance metric as above.
- Binary in disguise: Took the BAAI float vectors, converted them to binary, but kept the same float-friendly index and cosine distance.
- Binary done right: Stored the binary vectors in a binary index (BIN_FLAT) and used the Hamming distance.
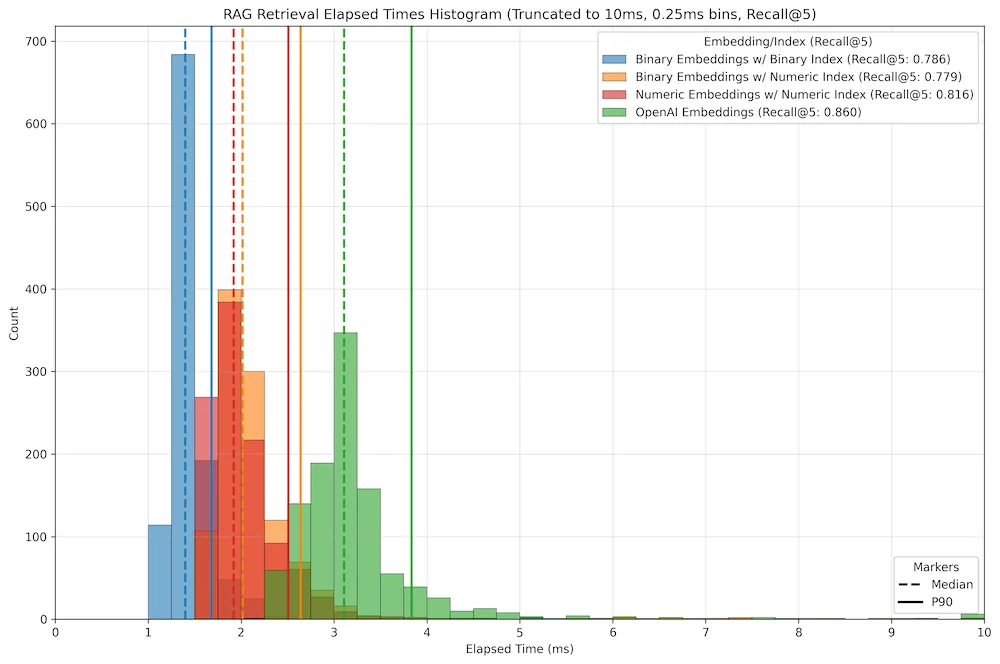
No surprise here: the binary embeddings in a binary index with Hamming distance were the Usain Bolt of the group. They sprinted past the floats, though they dropped a few batons in accuracy along the way. Interestingly, I noticed almost no difference between the float and binary embeddings when using the same index type and distance metric (with binary still edging ahead in speed). OpenAI embeddings were the slowest, as expected, since their vectors were 50% larger than those from the open-source model.
The experiment setup
For each test, I loaded 1,071 documents into a local vector database and queried them with PyMilvus. The setups looked like this:
The goal was simple: run the same semantic search under each configuration and see who came out on top in speed and accuracy.
The measured operation was the search call in Milvus, asking the database to return the top 5 matching documents for a single query vector. Each query was a question generated by the gpt-4o-mini model from the content of a document. In the results, the dashed vertical line marks the median time, the solid vertical line marks the 90th percentile, and the Recall@5 score is shown in the legend.
start = time.time()
search_result = client.search(
collection_name="documents",
data=[embedding],
limit=5,
output_fields=["title"]
)
end = time.time()
elapsed_ms = (end - start) * 1000
I obtained the binary vectors in the following ways:
import numpy as np
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-large-en-v1.5",
trust_remote_code=True,
cache_folder='./hf_cache',
device="cuda"
)
# for the float vectors with only 0s and 1s
def get_binary_embedding(text):
embeds = embed_model.get_text_embedding(text)
embeds_array = np.array(embeds)
binary_embeds = np.where(embeds_array > 0, 1, 0).astype(np.float32)
return binary_embeds
# for the binary vectors
def get_binary_embedding(text):
embeds = embed_model.get_text_embedding(text)
embeds_array = np.array(embeds)
binary_embeds = np.where(embeds_array > 0, 1, 0).astype(np.uint8)
packed = np.packbits(binary_embeds)
return packed.tobytes()
Speed vs accuracy tradeoff of binary embeddings
Binary embeddings are a neat trick for shrinking storage costs and speeding up searches. But like most tricks in machine learning, they come with a catch: in this case, slightly worse retrieval accuracy.
Would I deploy them in production today? No. In my experience, the real bottleneck in AI systems isn’t speed, but trust. Hallucinations break products faster than slow queries ever will.
I suspect fine-tuned binary embeddings could match OpenAI’s accuracy while keeping their speed advantage. If that’s true, we might finally get the best of both worlds. I’ll be testing that theory in future articles.