
This is one of the articles about "A.I. in production." It contains a story about a real company using A.I. in their products or building an MLOps tool.
This is NOT a sponsored content. I don't endorse the interviewed company and its products in any way. They don't endorse me either.
Do you have dozens of data quality tests but running them became cumbersome? I used to run my tests as a part of the Airflow DAG. It works fine until you have too many DAGs. Running custom test scripts in Airflow is not a big deal if you see only one or two failures a week. What if you have many pipelines? What if errors occur in multiple places at once? What if you need help from other people in the organization to fix them? It is time for a more advanced solution.
Recently, I spoke with Prukalpa Sankar - a cofounder of Atlan who built tools facilitating a collaborative data culture. Naturally, for me, the most interesting part was tooling for data quality profiling.
Atlan solves the problem by building a platform around other products such as Great Expectations or dbt. They let you run custom data profiling checks using engines like Great Expectations and present the result in a nice-looking web interface. That’s just a start. Prukalpa Sankar wants to solve the collaborative part of data quality, including the business context. What does it mean?
What typically happens when someone detects a data problem? First of all, someone has to catch it. In many companies, there is no automated way to do it. After that, you start a Slack/Teams/email discussion about the problem. Some people look at the pipelines to find where the data came from because there is no data lineage tool. Some others run custom analyses. Everyone involved in this has their favorite tool and analytics scripts - not compatible with each other.
Finally, when the team tracks the root cause, someone runs a few commands to fix the data. Nobody knows what commands were run because they don’t store them anywhere. They don’t even know whether they caused a new problem or not. In more mature teams, a senior data engineer may decide to “document” the issue in Confluence, so they create a page that never gets read and is quickly forgotten. Three months later, the team faces the same problem and has to do it all over again.
Can we use Atlan to do it better? When the Atlan platform finds a problem in the data, you can use the platform to discuss the issue, look up the data lineage in the built-in lineage tool, or review the data catalog. If that doesn’t help you, there is also an Excel-like data exploration tool that gives the power of data mining to non-technical users. You could also use the native integrations into JIRA and Slack to file tickets and collaborate with your team, all without leaving Atlan.
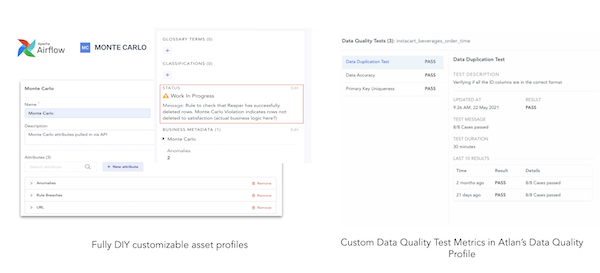
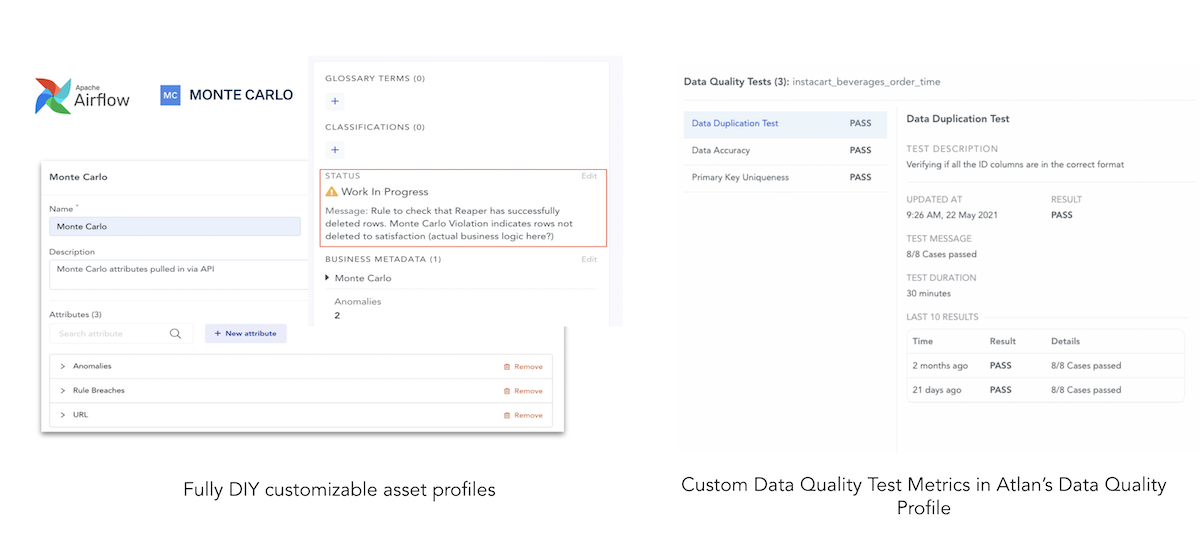
What else can Atlan do for you? As part of Atlan’s goal to be the home for metadata that provides a 360° view for data products, data profiling metrics can be generated from within the platform using packages from Atlan’s Marketplace (e.g. Great Expectations, Soda, etc). For more complex use cases, data quality metrics from external systems (custom checks, dbt tests, Monte Carlo, etc.) can be ingested to provide end users with visibility into data quality issues that might have arisen in the data pipeline. It can toggle the status of an asset so the user knows there’s a data quality issue.
{kind=link}