
As usual, I am going to use the Titanic dataset. It is possible to download it (and some other popular datasets) using the seaborn library.
Table of Contents
import seaborn as sea
import pandas as pd
import numpy as np
titanic = sea.load_dataset("titanic")
Which values are missing?
In the first step, I check which columns contain missing values. I am going to choose one of them and generate the values using Random Forest.
titanic.isnull().any(axis=0)
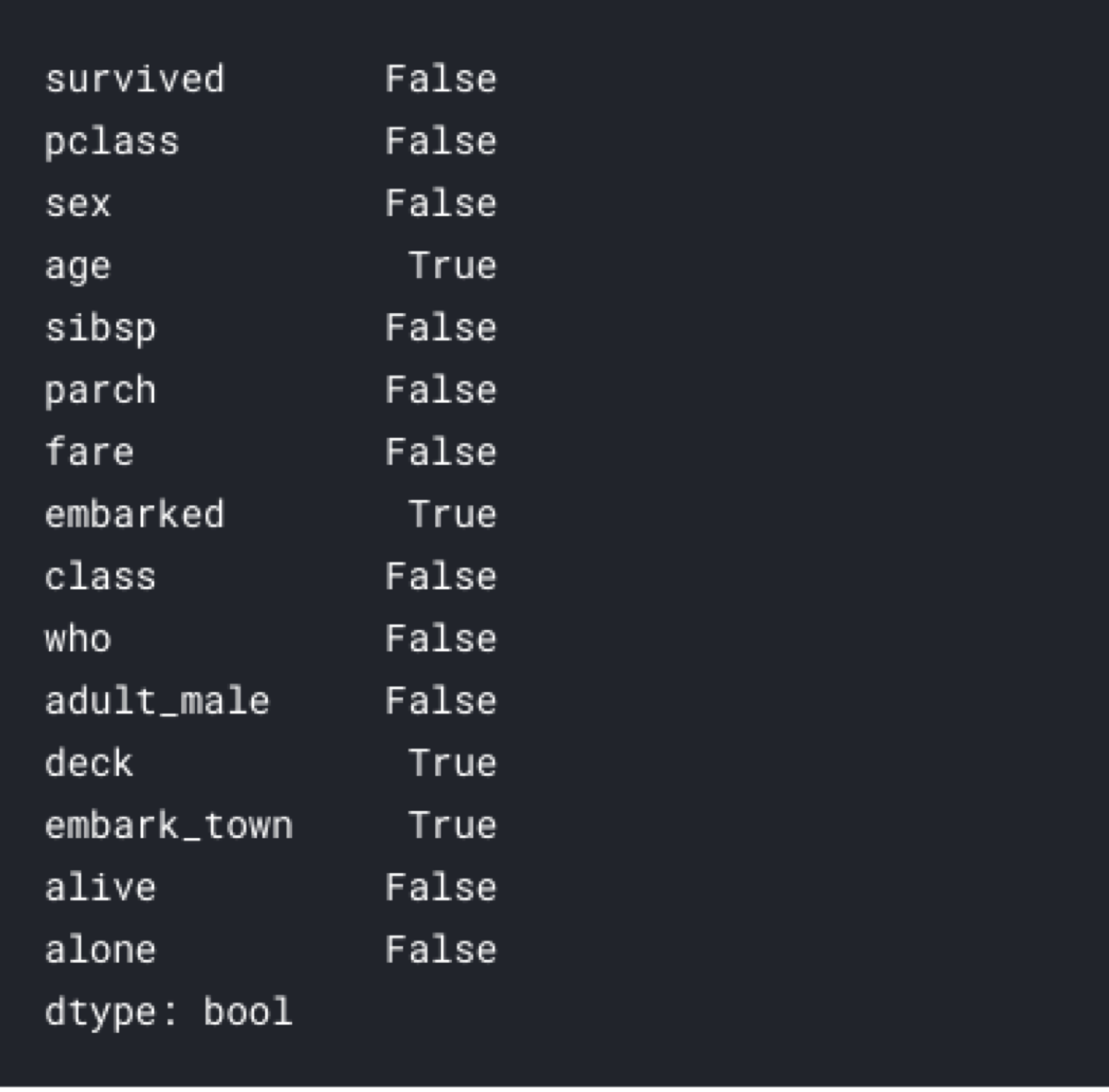
It looks like there are missing values in “age”, “embarked”, and “deck” columns.
I won’t include the code which I wrote to count the number of missing values because it is not essential in this example, so you have to trust me that I have checked that ;) You must know that there is so many missing values in the “deck” column that I probably cannot do anything about it. I have to drop that column it in the next step.
titanic = titanic.drop(columns = ['deck'])
I can attempt to predict the “age” and “embarked” columns. I think it is more interesting to predict the age, so let’s do that ;)
Preprocessing
Now it is time to split the Titanic dataset into two. The dataset which has non-empty age values will be used as the training data for the model.
from sklearn.ensemble import RandomForestRegressor
titanicWithAge = titanic[pd.isnull(titanic['age']) == False]
titanicWithoutAge = titanic[pd.isnull(titanic['age'])]
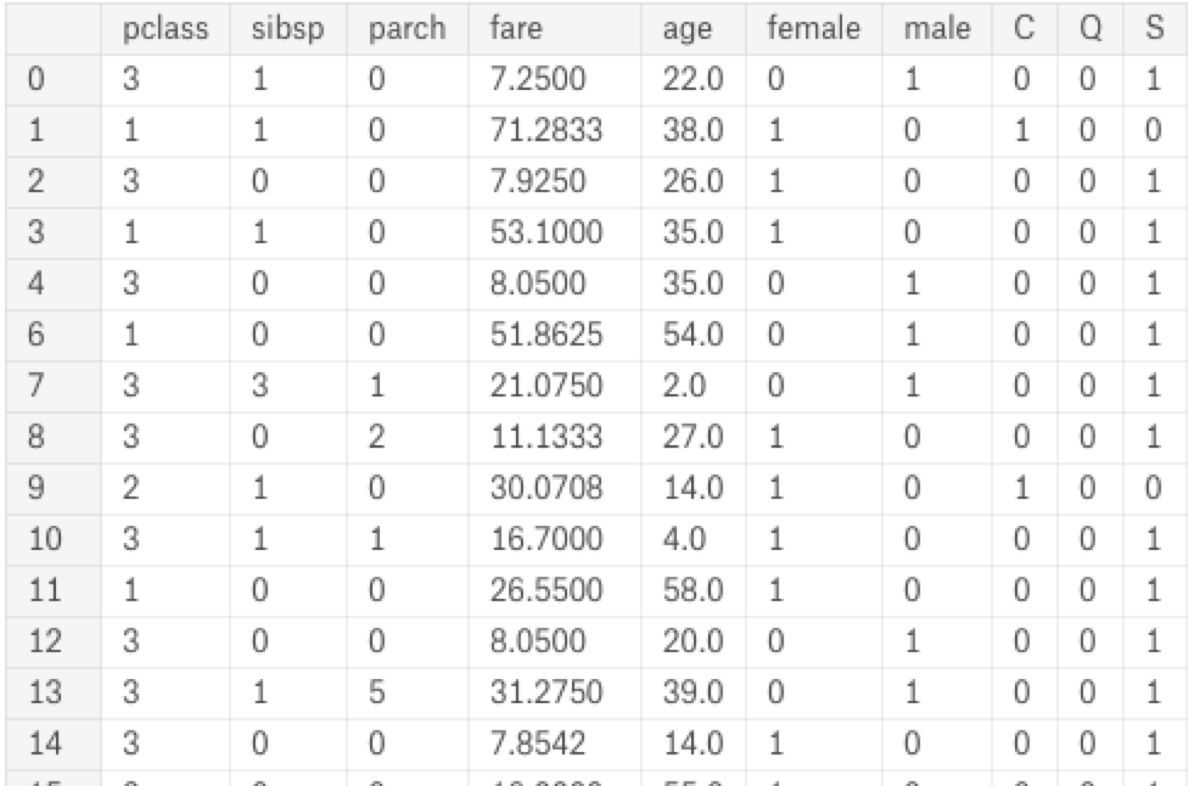
There are some duplicate columns in the Titanic dataset downloaded from Seaborn. The duplicates convey the same information encoded in two different ways. It is redundant and may negatively affect the model, so I must select a subset of columns.
variables = ['pclass', 'sibsp', 'parch', 'fare', 'age']
Additionally, categorical variables must be encoded as numeric values. This task can be done using one-hot encoding.
one_hot_encoded_embarked = pd.get_dummies(titanicWithAge['embarked'])
one_hot_encoded_sex = pd.get_dummies(titanicWithAge['sex'])
titanicWithAge = titanicWithAge[variables]
titanicWithAge = pd.concat([titanicWithAge, one_hot_encoded_sex, one_hot_encoded_embarked], axis = 1)
one_hot_encoded_embarked = pd.get_dummies(titanicWithoutAge['embarked'])
one_hot_encoded_sex = pd.get_dummies(titanicWithoutAge['sex'])
titanicWithoutAge = titanicWithoutAge[variables]
titanicWithoutAge = pd.concat([titanicWithoutAge, one_hot_encoded_sex, one_hot_encoded_embarked], axis = 1)
Prediction
Now the crucial part. It is the time to train the Random Forest regressor and predict the values of the “age” column.
independentVariables = ['pclass', 'female', 'male', 'sibsp', 'parch', 'fare', 'C', 'Q', 'S']
rfModel_age = RandomForestRegressor()
rfModel_age.fit(titanicWithAge[independentVariables], titanicWithAge['age'])
generatedAgeValues = rfModel_age.predict(X = titanicWithoutAge[independentVariables])
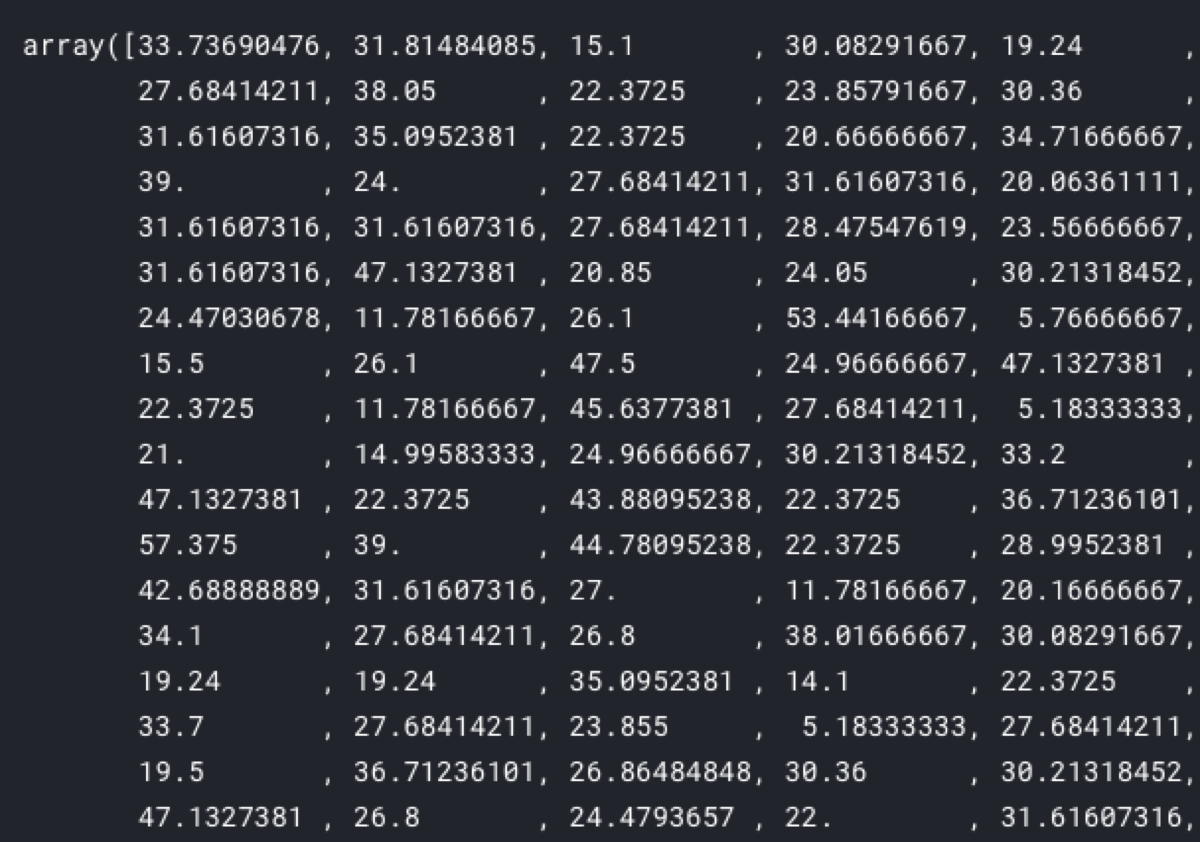
In the original dataset, the “age” column contains only integers, so I am going to cast the generated values to “int” and replace the missing age values with data predicted by the model.
titanicWithoutAge['age'] = generatedAgeValues.astype(int)
data = titanicWithAge.append(titanicWithoutAge)
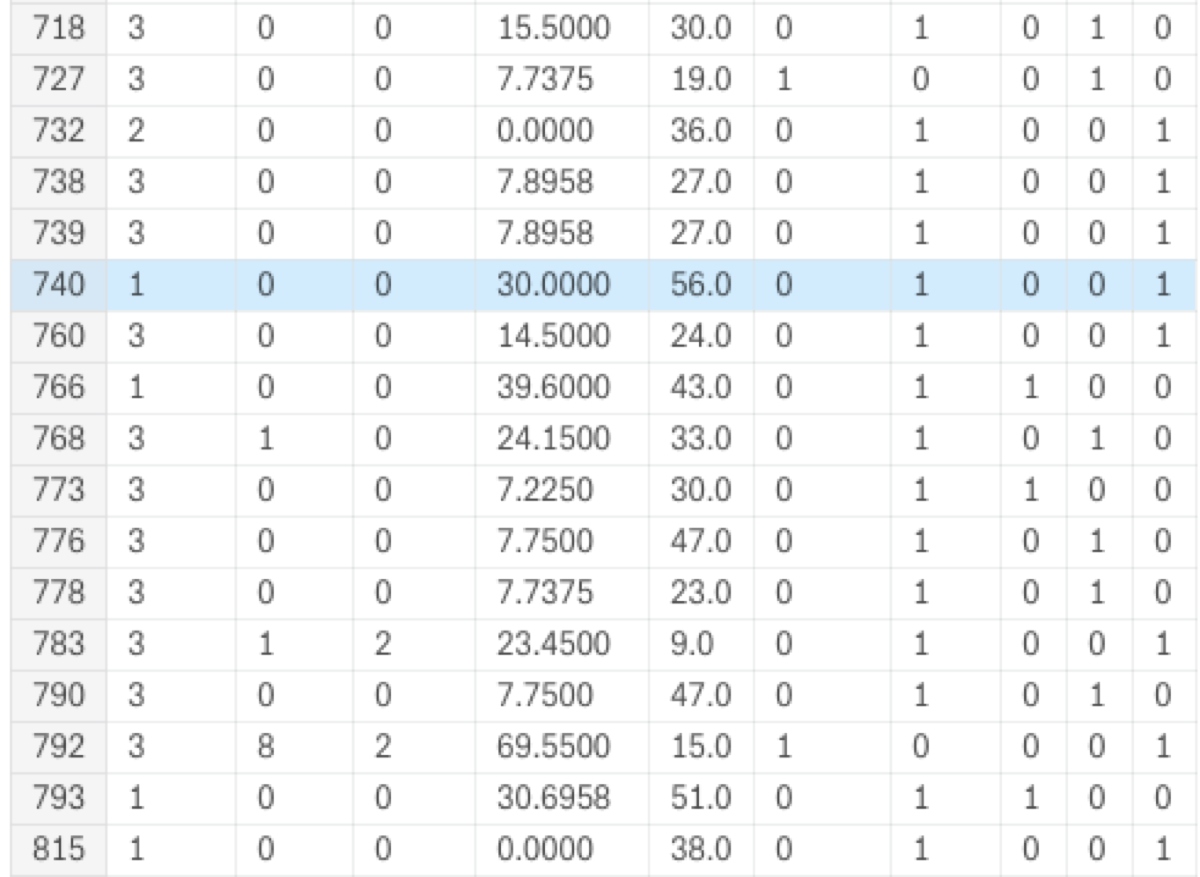
Last step! I have appended the data with generated age to the data used as the training set. As a consequence, the index looks like a mess.
Fortunately, I can quickly fix that by resetting the index and dropping the index column.
data.reset_index(inplace=True)
data.drop('index',inplace=True,axis=1)