
When using linear regression, it is crucial to remember that the dependent variable is expected to follow the Gaussian distribution.
Table of Contents
What can we do when it is not the case? Should we use a different kind of model or is there a way of fitting a linear model that works correctly even in the case of non-Gaussian distributions.
In this article, I am going to show how to use a Generalized Linear Model when the dependent variable follows the Poisson distribution. I am also going to describe the input parameters of the model and explain the essential parts of its output.
Example
First, I am going to generate the dependent variable and two independent variables randomly. Obviously, I can’t fit a good model to randomly generated data, but my goal is to explain the method, not to create a good model.
import numpy as np
y = np.random.poisson(lam = 5, size = 4000)
x1 = np.subtract(y, 2)
x2 = np.add(y, 1)
import pandas as pd
data = pd.concat([pd.Series(x1), pd.Series(x2), pd.Series(y)], axis = 1)
data.columns = ['x1', 'x2', 'y']
Now, I should look at the distribution of the dependent variable. For example, we can use the methods which I described in my article about Monte Carlo simulations. In this example, I don’t have to do it because I know what distribution I used to generate the data.
In the next step, I am going to convert a Pandas dataframe into data types which can be used by the statsmodels package. Note that “y” is my dependent variable. All of the independent variables (in this example: x1 and x2) must be specified on the right side of ~ using the plus sign to concatenate them.
from patsy import dmatrices
y, X = dmatrices('y ~ x1 + x2', data=data, return_type='dataframe')
When the input data is ready, I have to define the generalized linear model. Note that I had to pass an argument that denotes the distribution family of the dependent variable.
import statsmodels.api as sm
glm = sm.GLM(y, X, family=sm.families.Poisson())
Now, I can fit the model and look at the results object.
results = glm.fit()
print(results.summary())
How does it convert from Poisson distribution to Gaussian?
For every family of distributions, there is a function called “link function.” The link function “converts” the values calculated when the input is multiplied by the model coefficient. As a result, we get predictions which follows the same distribution as the dependent input variable.
Is it a good model? Where do I look?
When I print the result, I am going to get something like this:
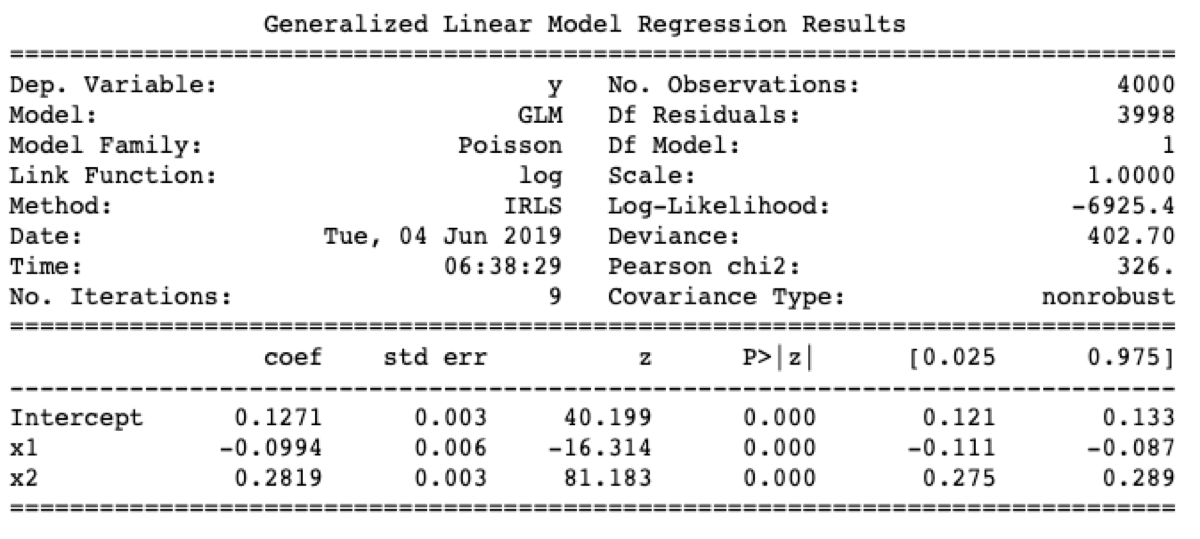
To compare different models generated using this method, we should look at the “deviance” variable in the result. The deviance is a generalized version of the residual sum of squares of the linear model.
Of course, when comparing different models, we can use the generated model to predict values of a test dataset, and use mean squared error or other metrics of your choice to get an error metric which does not depend on the algorithm used to fit the model.