
In this article, I am going to configure a Scrapy spider to store statistics about the retrieved content, show you how to send the statistics to InfluxDB, and configure a simple dashboard in Grafana. Additionally, I will configure an alert in Grafana to show a notification when a spider retrieves too few elements.
Table of Contents
Scrapy spider statistics
Every Scrapy spider has a stats object which, by default, stores the statistics in memory and prints them to the log when the spider finishes processing all URLs.
Default statistics
First, we will take a look at the automatically gathered metrics. Later, we will store a few values ourselves.
When a Scrapy spider finishes processing, it automatically dumps all its statistics to the log.
2019-09-08 09:31:48 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 834,
'downloader/request_count': 3,
'downloader/request_method_count/GET': 3,
'downloader/response_bytes': 131192,
'downloader/response_count': 3,
'downloader/response_status_count/200': 3,
'elapsed_time_seconds': 1.430534,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 9, 8, 7, 31, 48, 411973),
'item_scraped_count': 45,
'log_count/DEBUG': 48,
'log_count/INFO': 11,
'memusage/max': 47804416,
'memusage/startup': 47804416,
'response_received_count': 3,
'scheduler/dequeued': 3,
'scheduler/dequeued/memory': 3,
'scheduler/enqueued': 3,
'scheduler/enqueued/memory': 3,
'start_time': datetime.datetime(2019, 9, 8, 7, 31, 46, 981439)}
We see that by default, Scrapy stores information about the processing time, the number of requests, the size of transferred data, and the size of memory used for processing. It means that we don’t need to store such information manually.
Measuring dropped elements
In this tutorial, I will show you how to use the item pipeline to validate the parsed element and gather statistics regarding the number of invalid elements.
We have to begin by creating a component of the item pipeline. In Scrapy, such component is a class that implements a process_item function which accepts two parameters: the item and the instance of a Spider.
The extracted data returned by my Scrapy spider is stored in a dictionary which contains two values: title and URL. My ValidateUrl class retrieves the URL from the dictionary and uses a regular expression to check whether it is a valid link.
# note that I stored this class in the scrapers.processing module
import re
from scrapy.exceptions import DropItem
class ValidateUrl(object):
def __init__(self):
# Regex copied from https://codereview.stackexchange.com/questions/19663/http-url-validating
self.regex = re.compile(
r'^(?:http|ftp)s?://' # http:// or https://
r'(?:(?:[A-Z0-9](?:[A-Z0-9-]{0,61}[A-Z0-9])?\.)+(?:[A-Z]{2,6}\.?|[A-Z0-9-]{2,}\.?)|' # domain...
r'localhost|' # localhost...
r'\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}|' # ...or ipv4
r'\[?[A-F0-9]*:[A-F0-9:]+\]?)' # ...or ipv6
r'(?::\d+)?' # optional port
r'(?:/?|[/?]\S+)$', re.IGNORECASE)
def process_item(self, item, spider):
if re.match(self.regex, item['url']):
return item
else:
raise DropItem('Invalid url in %s' % item)
Now, I have to add the validator to the spider’s item processing pipeline. It can be done by adding the ITEM_PIPELINES to the custom_settings dictionary.
custom_settings = {
# other configuration elements
'ITEM_PIPELINES': {
'scrapers.processing.ValidateUrl': 1
}
}
When the extracted element contains a valid URL, nothing happens, but when the URL is invalid, the spider drops the extracted value and counts the number of dropped elements.
In the end, I am going to see two new entries in the statistics printed when the spider finishes processing the websites.
'item_dropped_count': 3,
'item_dropped_reasons_count/DropItem': 3,
Custom drop reasons
To define a custom drop reason, we have to extend the DropItem class.
class EmptyTitle(DropItem):
pass
Then, I can add a new validation rule and raise the EmptyTitle exception when the title is empty.
# Create a new item pipeline component and put this code in the process_item function.
# Remember to add the new component to ITEM_PIPELINES configuration.
if len(item['title']) == 0:
raise EmptyTitle('Title is empty')
When such a situation occurs, I am going to see my custom exception as an item dropping reason in the metrics:
'item_dropped_reasons_count/EmptyTitle': 8,
Adding own metrics
In the next step, I am going to show you how to store your custom metric. I am going to store the minimal and the maximal length of the title. I have to admit that it is not a very useful metric in real life, but we can use it as an example.
We can add the code in an item pipeline component which validates the length of the title.
First, we have to get the length of the title, and then we use two built-in functions max_value and min_value to store the current length of the title.
spider.crawler.stats.max_value('max_title_length', len(item['title']))
spider.crawler.stats.min_value('min_title_length', len(item['title']))
Those functions will compare the given length with the current maximal/minimal length and update the metric if we have passed a value that is greater/lesser than the current one.
When the spider finishes processing, the statistics write both values to the log.
'min_title_length': 4,
'max_title_length': 49,
All functions that you can use to gather metrics are described in the documentation: https://docs.scrapy.org/en/latest/topics/stats.html#common-stats-collector-uses
Sending metrics to InfluxDB
Now, we must implement a class that extends the StatsCollector class and provide a new implementation of the _persist_stats function.
InfluxDB entries consist of the measurement name, measurement time, tags, and measurement values. I specify all of those elements as a Python dictionary and send them to the database.
# note that I stored this class in the scrapers.metrics module
from influxdb import InfluxDBClient
import datetime
from scrapy.statscollectors import StatsCollector
class InfluxDBStatsCollector(StatsCollector):
def __init__(self, crawler):
super(InfluxDBStatsCollector, self).__init__(crawler)
#REPLACE WITH YOUR DB CONFIGURATION!!!
self.client = InfluxDBClient(host, port, username, password, database)
def _persist_stats(self, stats, spider):
time = datetime.datetime.utcnow().isoformat()
measurements = [{
"measurement": "scrapy_spiders",
"tags": {
"spider_name": spider.name
},
"time": time +"Z",
"fields": {
'request_bytes': stats.get('downloader/request_bytes', 0),
'response_bytes': stats.get('downloader/response_bytes', 0),
'elapsed_time_in_seconds': stats.get('elapsed_time_seconds', 0),
'item_scraped_count': stats.get('item_scraped_count', 0),
'max_title_length': stats.get('max_title_length', 0),
'min_title_length': stats.get('min_title_length', 0),
'empty_title': stats.get('item_dropped_reasons_count/EmptyTitle', 0),
'item_dropped_count': stats.get('item_dropped_count', 0)
}
}]
self.client.write_points(measurements)
When the class is ready, we must configure the spider to use the new statistics collector code. Remember to create the database in InfluxDB!
custom_settings = {
# other configuration elements
'STATS_CLASS': 'scrapers.metrics.InfluxDBStatsCollector'
}
To test whether the metrics were stored correctly, I send a query using the InfluxDB REST API and retrieve all values from my measurements collection.
curl -G 'http://localhost:8086/query?pretty=true' \
--data-urlencode "db=spider" \
--data-urlencode "q=SELECT * FROM scrapy_spiders"
Response:
{
"results": [
{
"statement_id": 0,
"series": [
{
"name": "scrapy_spiders",
"columns": [
"time",
"elapsed_time_in_seconds",
"empty_title",
"item_dropped_count",
"item_scraped_count",
"max_title_length",
"min_title_length",
"request_bytes",
"response_bytes",
"spider_name"
],
"values": [
[
"2019-09-08T09:30:21.111323136Z",
2.376386,
0,
0,
45,
44,
4,
834,
131677,
"test_spider"
]
]
}
]
}
]
}
Create Grafana dashboard
Add InfluxDB as a data source
Log in to Grafana, in the menu select “Configuration” -> “Data sources,” click “Add data source,” select “InfluxDB,” provide the database configuration and click the “Test & Save” button.
Configure dashboard of dropped elements
Select the “New dashboard” option in Grafana. In the “New Panel” window click the “Add Query” button.
Click the “Toggle text edit mode” and write the InfluxDB query to retrieve the time series data. In the case of my spider, the query to retrieve the dropped elements looks like this:
SELECT "item_dropped_count" FROM "scrapy_spiders" WHERE $timeFilter
Configure alerts
In the dashboard’s edit view, click the “Alert” button. In this window, we have to select the time window (in this example, 5 minutes), the alert checking interval (every 1 minute), and the aggregating function (average).
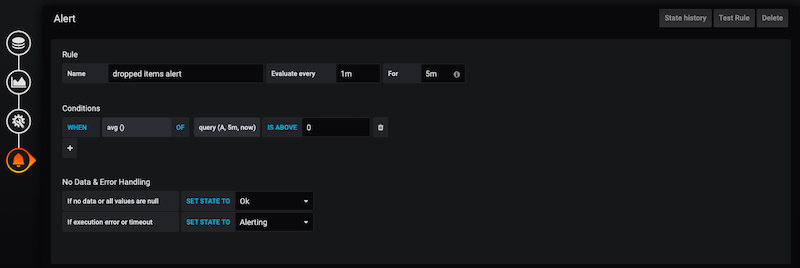
When the average number of dropped elements in the defined time window exceeds the threshold, the alert’s status will switch to “pending.” If the measurement keeps exceeding the threshold for at least the duration of the time window, the alert will switch status to “alerting,” and Grafana starts displaying/sending notifications (if you configured alert notifications).