
One of the common concerns I heard while teaching workshops about AI to business people was how to ensure employees aren’t leaking personal data to AI models. The only things preventing data leaks are proper training and awareness of consequences, but we can automate monitoring and detect when someone leaks the data. This is one aspect of building safer AI systems with content moderation.
Table of Contents
- Providing Controlled Access to ChatGPT
- Setting Up Data Leak Detection
- Looking For Leaked Data
- Preserving an Audit Trail
Providing Controlled Access to ChatGPT
Unfortunately, we can’t intercept the requests to ChatGPT, so we will have to setup an alternative web interface similar to ChatGPT where we have control over the requests. HuggingChat offers access to open-source models hosted by HuggingFace with a UI similar to ChatGPT. However, we won’t use any of the open-source models. Instead, we will configure the tool to use the OpenAI API and send requests to GPT4.
The first thing we need to do is download the web application from the GitHub repository: https://github.com/huggingface/chat-ui
Before we start the app, we need a MongoDB database for storing the history of conversations, an OpenAI API key, and a configuration to overwrite the default models with OpenAI. Additionally, we must modify one line in the HuggingFace source code.
For the demonstration purposes, we will install everything locally. If you want to deploy the chat in production, remember to build a prod version of your HuggingChat app after making all the required changes (see the official repository for instructions).
First, we start the MongoDB server: docker run -d -p 27017:27017 --name mongo-chatui mongo:latest
After that, in the root directory of HuggingChat, we create a .env.local file. The file will contain all of the environment variables with the service configuration. In production, you can pass them as actual environment variables.
In the config file, we need the MongoDB server address, OpenAI API key, and the configuration of available models.
MONGODB_URL=mongodb://localhost:27017
OPENAI_API_KEY=sk-...
MODELS=`[{
"name": "gpt-4",
"displayName": "GPT 4",
"endpoints" : [{
"type": "openai"
}]
}]`
Additionally, you should set up authentication in HuggingFace to distinguish between users. The official documentation provides instructions with all of the required steps: https://github.com/huggingface/chat-ui?tab=readme-ov-file#openid-connect
When we start the HuggingChat, we should be able to send a request to OpenAI’s GPT4.
Setting Up Data Leak Detection
We will use the GPTBoost service to log the queries and detect data leakage. The service works as an intermediate endpoint intercepting requests sent to OpenAI. Therefore, we will need to modify the OpenAI URL used by HuggingFace. To correctly attribute a request to our GPTBoost account, we must add the OpenAI API key in the account’s settings before sending any requests.
Seemingly, it should be enough to add the “URL” property to the “endpoints” JSON in the MODELS environment variable, but configuring the URL didn’t work in the version I tested. Therefore, we have to look for the https://api.openai.com/v1 URL in the HuggingChat source code and replace the value with GPTBoost endpoint: https://turbo.gptboost.io/v1.
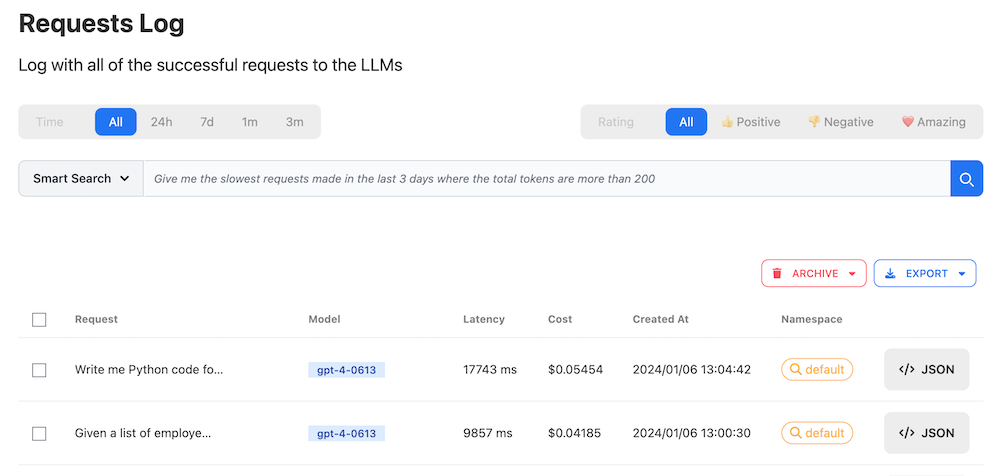
GPTBoost will log every request sent from our HuggingFace application. We will also see the cost of processing the request.
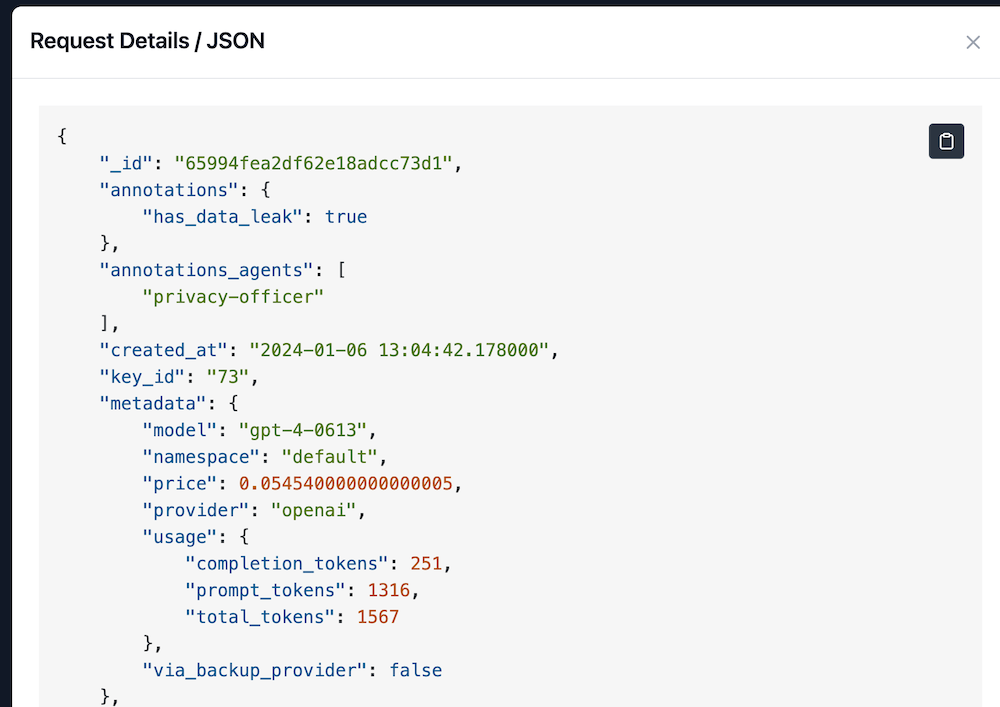
Now, we have to configure an annotation agent to detect data leaks. The pre-defined Privacy Officer Agent will look for PII, usernames, passwords, social security numbers, etc. If the agent finds such data in the request, the request will be marked as containing a data leak.
Let’s give it a try. I want to check if the agent detects a leaked password. I provided a username and password to some fake server in my request.
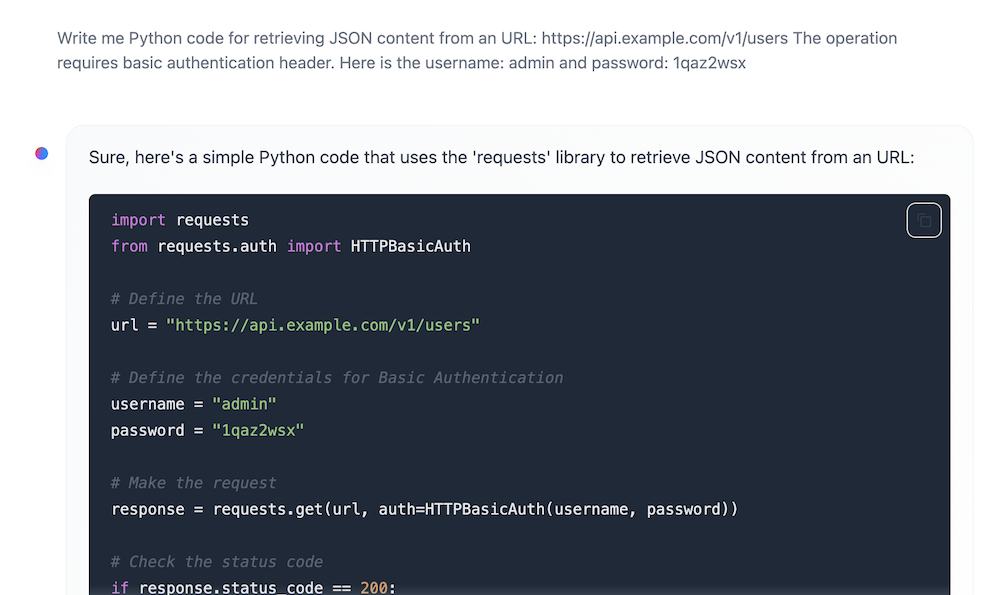
The agent correctly flags the request as a data leak.
Looking For Leaked Data
Flagging a request isn’t useful if you can’t find such requests later. Fortunately, the request log offers an AI-powered search box where you can type what you are looking for, and the search automatically generates the corresponding query:
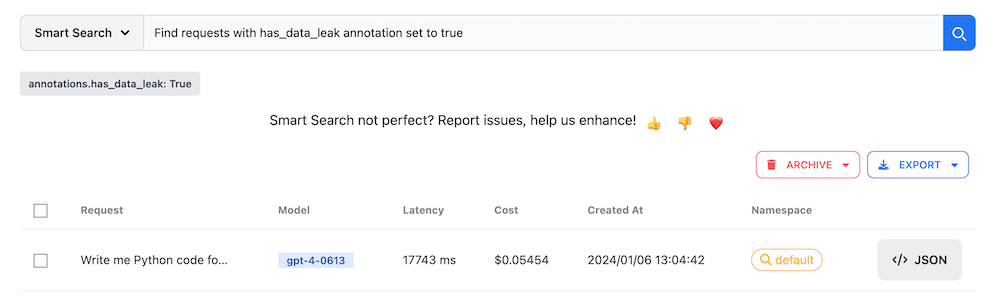
Preserving an Audit Trail
GTPBoost stores the requests, responses, and tags added by agents, but it doesn’t store any information about the user who performed the query. We would need a separate HuggingChat instance with separate OpenAI API keys to distinguish between users.
A little bit of data engineering will give us better results and more practical architecture.
We need a pipeline copying data from MongoDB into a data lake or a separate database where the requests stay forever. In GPTBoost, we have the full user’s input and the request’s correlation ID generated by OpenAI. With those two values, we can easily find a corresponding conversation in the data copied from MongoDB. If we configure authentication, MongoDB will also contain information sufficient to identify the user.
If you want to modify HuggingChat even more, consider using the GPTBoost Props feature. The feature allows us to log the headers added to the ChatGPT call to include the user’s ID in the request and avoid copying data from MongoDB. Remember that the extra headers are sent to both GPTBoost and OpenAI. Pay attention to what you send to avoid leaking data while building a data leak prevention tool.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn