
“Look at your data.” I’ve said this so often that some of my clients probably hear it in their sleep. But when a €20 million GDPR fine is on the line, those four words become the difference between a successful AI implementation and a career-ending disaster.
Table of Contents
- What Engineering Leaders Get Wrong About AI Implementation
- The Systematic AI Improvement Process That Actually Works
- The Unspoken Truth Every Engineering Leader Needs to Hear
- What You Can Do Today
A client of mine wanted to censor the prompt sent to the OpenAI model to avoid leaking personal information. The client was worried that with OpenAI’s “relaxed” approach to copyright law, they may have a similarly relaxed approach to their promise of not using the client’s data for training. Their idea was to use a small, open-source model to find personal data and replace it with a placeholder before sending the prompt to the OpenAI model.
The client’s team created the first version of the solution using an open-source Named Entity Recognition model. The performance of the first version was barely good enough to show during a product demo. The model was supposed to detect three kinds of data (which I can’t tell you about…), and it achieved a decent 92.5% accuracy on entity type 1, a laughable 37% on entity type 2, and an utterly useless 0.3% on entity type 3. With an average accuracy of 43.2%, the model wasn’t even good enough to be called a proof of concept. But I knew I could fix it.
What Engineering Leaders Get Wrong About AI Implementation
Here’s what I’ve observed after years of watching AI projects fail: Engineering teams obsess over model architecture when they should be obsessing over error analysis.
The typical approach:
- Try a fancy new model
- Get mediocre results
- Try an even fancier model
- Get slightly better results
- Declare victory or blame the technology
This is why most AI implementations remain stuck in the perpetual “demo” phase, never reaching production reliability. But there’s a simpler, more effective approach.
Let me show you how we achieved production-ready results using an ordinary model in less than 30 hours of work without requiring expensive GPUs or the latest models.
The Systematic AI Improvement Process That Actually Works
Instead of chasing the latest models, we focused on a three-step process:
Step 1: Look at the Data (Especially the Failures)
I built a custom data review tool in 20 minutes (yes, using AI to help implement a tool for reviewing AI results). This tool let me quickly review every error case, revealing a pattern: the model consistently split long entities that should have been connected.
Imagine the model detecting phone numbers (just an example, phone numbers weren’t one of the detected entities in this project). In this case, our baseline model would treat the text (555) 555-1234 as three separate phone number entities: (555), 555, and 1234. Of course, if this was the only problem, we could write code to merge entities of the same type with a single space between them and call it a day. But it wasn’t the only problem.
This insight highlights why manual review remains essential in the AI era. Automated metrics alone can’t reveal the specific patterns of failure that hold your system back. For a detailed guide on this approach, see my article on why data analysis matters for AI improvements.
Step 2: Automate Metrics That Actually Matter
Next, I created an “AI judge” using an LLM to evaluate results automatically. But here’s the critical step most teams miss: I built a testing framework to ensure the judge’s evaluations aligned with human judgment. This created a reliable feedback loop.
I realized that BAML is a perfect tool for ensuring alignment. You can define the expected behavior as tests and easily check if the LLM-as-a-judge handles them correctly.
This case demonstrates that automated testing is even more critical for AI systems than traditional software. While traditional systems fail in predictable ways, AI can produce novel failures that only comprehensive testing can catch. The testing problem becomes even more complex when you use AI to test AI. Without proper testing, I would have never been able to ensure the LLM-as-a-judge was aligned with human judgment.
Step 3: Tweak the Model Systematically
With reliable metrics in place, I created targeted training examples that addressed the problems identified in the data review and fine-tuned our model.
After several iterations, the results shocked even me:
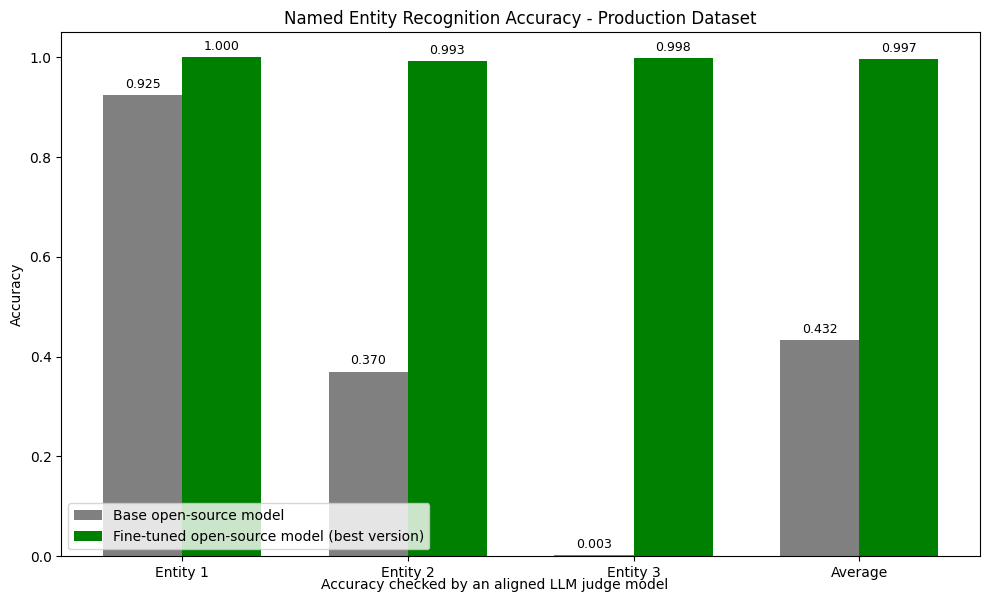
- Entity 1: 100.0% accuracy (↑ 7.5 pp)
- Entity 2: 99.3% accuracy (↑ 62.3 pp)
- Entity 3: 99.8% accuracy (↑ 99.5 pp)
- Overall: 99.7% accuracy (↑ 56.5 pp)
These results effectively eliminated the €20M regulatory risk, transforming a potential liability into a robust security layer.
The entire implementation took less than 30 hours, spread across a week.
What’s truly remarkable is that I achieved these results using a year-old, open-source transformer model. I didn’t need LLaMA-4, DeepSeek-V4, or Qwen 2.5. The solution required only a reliable, affordable model that doesn’t even need a GPU to run. This approach delivered superior results at a fraction of the cost of using premium models. Once again, this proves that systematic implementation trumps throwing money at expensive AI.
The Unspoken Truth Every Engineering Leader Needs to Hear
Here’s what I wish someone had told me years ago:
You fix errors by analyzing errors, not by chasing general metrics.
Most engineering teams track overall accuracy, F1 scores, or other aggregate metrics. But these numbers hide the specific failures that matter most in production.
When a potential €20 million GDPR fine hinges on your system’s reliability, those hidden errors aren’t just technical problems, but they’re existential threats.
The One Question That Changes Everything
If you’re an engineering leader implementing AI, ask yourself this:
“How will I know that we’ve achieved the goal of the system?”
Not “What model should we use?” or “What’s our accuracy target?”
The answer to that question reveals the metrics that matter. The prompt censorship model aimed to ensure that the prompt sent to the OpenAI model doesn’t contain personal data. The target metric was the 100% accuracy in detecting personal data.
What You Can Do Today
If you’re struggling with AI implementation, the solution isn’t more complex models, bigger datasets, or fancier techniques.
It’s a systematic approach to identifying and fixing errors:
- Look at your data, especially where your system fails
- Automate metrics that align with real-world success criteria
- Tweak your model with a laser focus on specific error patterns
This approach doesn’t just work for NER models. It works for any AI system you’re trying to bring to production, whether you use third-party hosted models, train your own models, use a pre-trained open-source model, or do a combination of all of them.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn