
Developing AI-based applications is a nightmare. Models return inconsistent responses. Any change to the prompt requires extensive testing because your new feature may cause tons of regression bugs. And, of course, forcing AI to return a JSON parsable response reliably is nearly impossible, even when you use JSON mode.
Table of Contents
An average custom implementation of AI-based software costs between 20,000 and 50,000 USD. We waste the money if we can’t trust the result. If we can’t get reproducible results, we should probably stop using the word “engineering” when discussing AI engineering. Still, large language models are tremendously useful, so we must continue building applications with generative AI.
It’s time to put engineering back into AI engineering. With BAML, we can define structured output formats, parse the AI response automatically even if it doesn’t fully conform to the expected output format, define tests for our prompts, hide the retry code from the rest of the application, and build a simple interface backend engineers can use.
The Design Philosophy Behind BAML
According to Vaibhav Gupta the CEO of Boundary ML (the company behind BAML), we are now at the same stage of prompt engineering as frontend engineering was before React was created. Building a website was like working with a magical string that made the browser display something on the page. You needed a slightly different string for every browser and making a change in the code took minutes because you needed to navigate to the same part of the application and hope the state is preserved.
The current approach to prompt engineering is broken in a similar way to pre-React frontend engineering. We have a magical string - the prompt. Every AI model needs a slightly different kind of prompt, and iterations take minutes because passing the state to the prompt and from the response requires changing the prompt and the data model simultaneously while keeping them compatible.
Also, when we build with AI, we suddenly deal with systems in which a 5% failure rate is normal. Models may be unavailable or return a response your code cannot parse correctly. Fault-tolerant systems are hard, and now everything must be fault-tolerant.
Backend engineers aren’t to working with such faulty systems. In most cases, you can assume your database works, the APIs you use work, etc. If they don’t, your application doesn’t work either. But AI is way too unreliable to make such an assumption. We must bring fault tolerance to the AI calls. BAML does it.
And BAML does it better than the existing prompt engineering frameworks because BAML doesn’t hide the prompt from the AI engineers. Prompt is the most important thing, and you should see it. Using a tool that hides the prompt would be like using a frontend framework that hides the HTML sent to the browser. Good luck debugging such code.
Vaibhav Gupta says:
React made frontend engineering actual engineering. BAML makes prompt engineering actual engineering.
Why Should You Use BAML?
As an AI engineer, you should use BAML to create an isolated module hiding all the complexity of using AI. Some backend engineers think AI is just another API. It’s not. But with BAML, we get really close to treating AI as yet another API. The model may still make mistakes. The examples you put in the prompt may become irrelevant, and you will have to deal with the data drift. After all, it’s still machine learning. MLOps engineers are used to dealing with such issues, while BAML deals with the failures we have never seen before.
How Does BAML work?
Suppose we build an application for analyzing online reviews (similar to the one I present in this case study), but instead of using AI client libraries directly, parsing outputs, and handling errors, all we need to write in the application code is this:
from baml_client import b
analysis = b.AnalyzeReview(review_text)
Prompt generation, output parsing, and error handling happen inside the code generated by BAML. All we have to do is create the data model and the prompt template.
Data Model in BAML
As a result, we may get a Pydantic class with the following content:
tags=[Review(quote="The promised completion time was 3pm, but when I arrived at 3pm, they hadn't even started on my bikes.", tag=<NegativeTags.SLOW_SERVICE: 'SLOW_SERVICE'>), Review(quote='Some repairs were incomplete while others had unnecessary work done.', tag=<NegativeTags.POOR_REPAIR: 'POOR_REPAIR'>), Review(quote="I didn't get my bikes back until almost 5pm, and for $200+ in repairs, it was quite frustrating.", tag=<NegativeTags.OVERPRICED: 'OVERPRICED'>)] sentiment=<SentimentValues.NEGATIVE: 'NEGATIVE'>
How do we define a data model in BAML? We need a BAML file with the class definition and all of the enums we use. BAML will use the definition to generate the classes in our chosen language (Python, Typescript, Ruby, or a REST API definition). The data model definition consists of the types and a description that provides a hint for the AI regarding when and how to use the fields or enum types.
enum PositiveTags {
QUALITY_REPAIR @description("High-quality repair work")
FAST_SERVICE @description("Quick turnaround time")
FRIENDLY_STAFF @description("Friendly and helpful staff")
...
}
enum NegativeTags {
POOR_REPAIR @description("Subpar repair quality")
SLOW_SERVICE @description("Long wait times for repairs")
RUDE_STAFF @description("Unfriendly or unhelpful staff")
...
}
enum SentimentValues {
POSITIVE @description("Positive")
NEGATIVE @description("Negative")
NEUTRAL @description("Neutral")
MIXED @description("Mixed")
}
class Review {
quote string @description("Quote extracted from the text")
tag PositiveTags | NegativeTags @description("The extracted review tag")
}
class ReviewAnalysis {
tags Review[] @description("What are the tags of the given review?")
sentiment SentimentValues @description("Sentiment of the review")
}
AI Prompts in BAML
Where do you put the prompt? In the same file as the data definition, we can define functions. Each function will be converted into a client function that sends the generated prompt to the selected AI model and parses the response as a class in the client’s programming language.
The function defines the model used by the BAML library and the template of the prompt. The template must contain the output format variable, and we can include any number of other variables we have:
function AnalyzeReview(review: string) -> ReviewAnalysis {
client "openai/gpt-4o-mini"
prompt #"
Given a bicycle repair shop review, choose up to three positive or negative tags from the list defined below.
For each tag, start with a quote explaining the tag. Add only one tag per quote.
{{ ctx.output_format }}
{{ review }}
"#
}
The final step is providing the client definition and a retry policy in case of problems with the AI model. After configuring a custom client, we have to go back to the function definitions and replace the client property with the custom client class (in the example below, it would be CustomGPT4oMini).
client<llm> CustomGPT4oMini {
provider openai
retry_policy Exponential
options {
model "gpt-4o-mini"
temperature 0.0
api_key env.OPENAI_API_KEY
}
}
retry_policy Exponential {
max_retries 2
strategy {
type exponential_backoff
delay_ms 300
multiplier 1.5
max_delay_ms 10000
}
The code I have shown you so far is sufficient to generate the client module shown earlier and use the AI in the application (if you provide the OPENAI_API_KEY as the environment variable).
Seeing the Actual Prompt
The prompt wasn’t supposed to be hidden from us. Where can we see it? If you install the BAML Playground extension for Cursor (or VSCode), you can use the extension to preview the entire generated prompt.
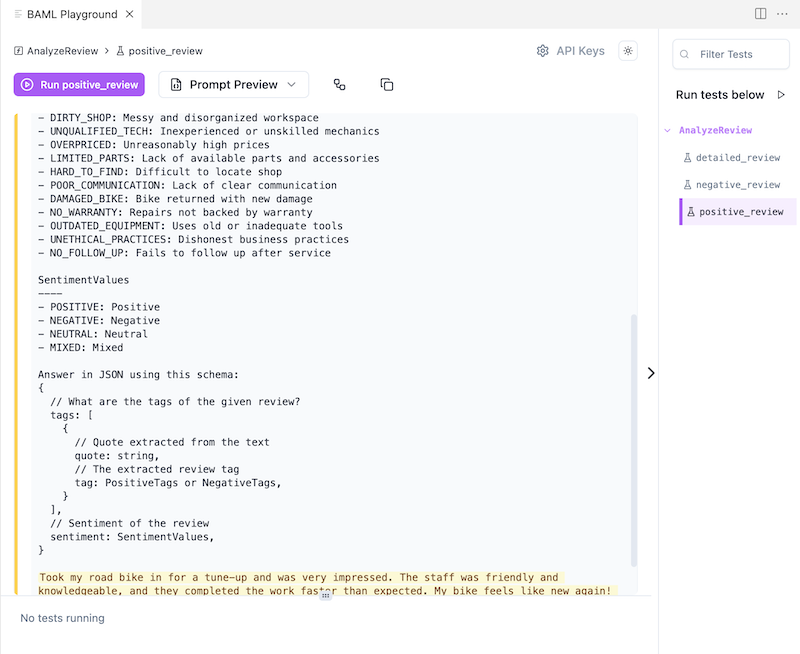
Testing the Prompts
We can also run the tests defined in the BAML file in the same extension. But first, let’s define a test.
A test consists of the function it’s supposed to call and the arguments for the function. Optionally, we can also define automated assertions. You don’t need them if you prefer to manually review the results every time you run the tests. However, writing code with no tests is just “vibe coding.” And it doesn’t matter if the code was AI-generated or you wrote the code yourself. Proper software engineering requires automated testing.
You may think AI is unpredictable, so the tests may be flaky. It’s possible. But if you can’t get reliable results from a handful of handcrafted test cases, you shouldn’t even think of putting the same code in production.
test positive_review {
functions [AnalyzeReview]
args {
review #"
Took my road bike in for a tune-up and was very impressed. The staff was friendly and knowledgeable, and they completed the work faster than expected. My bike feels like new again! They even pointed out a few potential issues I should keep an eye on. Highly recommend this shop for any cyclist.
"#
}
@@assert(must_have_reviews, {{ this.tags | length > 0 }})
@@assert(must_have_friendly_or_fast_service, {{ this.tags[0].tag == "FAST_SERVICE" or this.tags[0].tag == "FRIENDLY_STAFF" }})
@@assert(must_be_positive, {{ this.sentiment == "POSITIVE" }})
}
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn