
Calls to LLM models take a substantial amount of time, even when we use expensive hardware or a paid API. If we use LLMs in production with structured data, we often send the same request multiple times. We can save time and money by caching the results of the API calls.
Table of Contents
- Langchain caching model API calls
- Langchian caching embeddings API calls
- Internals of Langchain caching
Naturally, we can handle caching in several ways. One option would be to group the same request, send a single API call, and assign the same response to all requests. Another option would be to cache the answer in a database (or in memory) and write code to check if the response is already in the cache before sending the request to the API.
But we don’t need to write the caching code. Langchain already offers a caching mechanism for all supported LLM models.
The following code uses langchain version 0.0.268.
Langchain caching model API calls
To use the Langchain caching code, we need to import the Langchain adapter for the LLM API we want to call. For example, in the case of OpenAI API, we import from langchain.llms import OpenAI or from langchain.chat_models import ChatOpenAI.
When we have the API adapter, we have to setup the cache. For the first example, I will use the in-memory caching option. I have to import the langchain module too!
Before we send any call to the LLM, we have to set the llm_cache variable in the langchain module.
The current implementation is a little bit cumbersome. We set a global cache for all kinds of LLMs and all instances of the LLM adapter. We can have only one cache for all interactions — unless we juggle with the llm_cache variable and reassign the value every time we want to change the cache at runtime. Hopefully, the implementation will get improved in a future version of Langchain.
import langchain
from langchain.cache import InMemoryCache
langchain.llm_cache = InMemoryCache()
When we call the predict function, Langchain will cache the response. The next time we call the predict function with the same arguments (the same prompt and the same LLM parameters), the cache will serve the response.
llm = OpenAI(model="text-davinci-003", openai_api_key='sk-...')
llm.predict(prompt)
Storage Options
Currently, we have only two options: an in-memory cache or a local SQLite database. In the case of a database, the caching code would look like this:
from langchain.cache import SQLiteCache
langchain.llm_cache = SQLiteCache(database_path=".langchain_cache.db")
Tracking Cached Requests in Langsmith
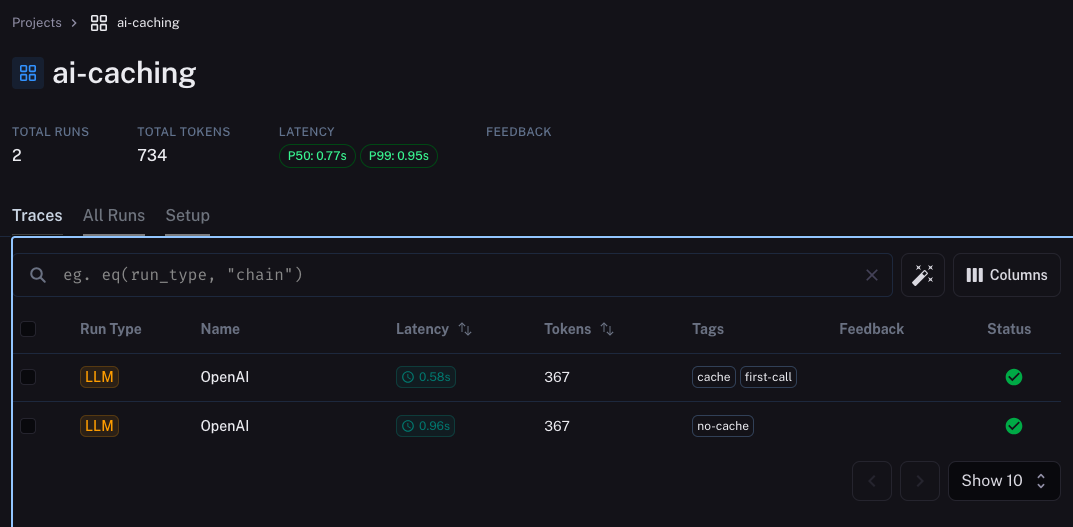
When we use Langsmith for tracking LLM interactions (as I described in this article), we won’t see the cached requests on the Traces list. It happens because when we get a response from the cache, Langchain doesn’t call an LLM.
I sent four exact requests to the API. The first was with a disabled cache, so Langchain sent the request to the LLM. The second one was with the cache enabled, but the cache was empty, so the request was sent to the API, too. Langchain served the third and fourth requests from the cache, so Langsmith didn’t receive any tracking data.
llm.predict(prompt, tags={'no-cache'})
llm.predict(prompt, tags={'cache', 'first-call'})
llm.predict(prompt, tags={'cache', 'second-call'})
llm.predict(prompt, tags={'cache', 'third-call'})
Langchian caching embeddings API calls
In addition to caching the LLM responses, we can cache the responses of the embeddings API too. The currently available API for embeddings caching is way better than LLM caching because we don’t have a single global cache. Instead, we explicitly create a cached embeddings client with a specific storage option:
from langchain.storage import InMemoryStore, LocalFileStore, RedisStore
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
store = InMemoryStore()
underlying_embeddings = OpenAIEmbeddings(openai_api_key='sk-...')
cached_embedding = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings, store, namespace=underlying_embeddings.model
)
cached_embedding.embed_documents([document_A, document_B, ...])
Storage Options
Embeddings caching offers three storage options. In addition to an in-memory cache, we can use a local filesystem or Redis as a storage backend:
from langchain.storage import LocalFileStore, RedisStore
store = LocalFileStore("./local_directory")
# or
store = RedisStore(redis_url="redis://localhost:6379", client_kwargs={'db': 2}, namespace='embeddings')
Internals of Langchain caching
Naturally, we want to know the values stored in the cache and have an option to selectively(!) remove cached values. Let’s take a look at the internals of the implementations.
LLM Cache
In the case of LLM caching, we see that the values are stored using a tuple consisting of the entire prompt and the LLM parameters as the key:
langchain.llm_cache._cache
I censored the values a bit, but I didn’t change the structure.
{('Find the email address in the given text:\n\n```REMOVED_TO_SHORTEN_THE_EXAMPLE```\n',
"[('_type', 'openai'), ('frequency_penalty', 0), ('logit_bias', {}), ('max_tokens', 256), ('model_name', 'text-davinci-003'), ('n', 1), ('presence_penalty', 0), ('request_timeout', None), ('stop', None), ('temperature', 0.7), ('top_p', 1)]"): [Generation(text='REMOVED_FROM_THE_EXAMPLE', generation_info={'finish_reason': 'stop', 'logprobs': None})]}
Unfortunately, the API doesn’t offer any way to remove a single value from the cache. We can only clear the entire cache using the public functions:
langchain.llm_cache.clear()
To remove a single value, we have to look at the internal implementation and remove the value from the _cache dictionary (or from the table in the case of the SQLite cache).
Embeddings Cache
The embeddings cache API doesn’t offer a better developer experience. We can list the keys of the cached embeddings, but when we do it, we realize the keys are model names and hashes of the documents:
list(store.yield_keys())
['text-embedding-ada-0024f6b2ee3-6805-5a0e-be26-54589159b3b8',
'text-embedding-ada-00213951557-8a29-5695-81d7-bad64b875d22',
'text-embedding-ada-002db52eb56-1683-52b2-adc6-220f47308e0f']
We can retrieve or remove elements using those keys. However, generating a proper key would require looking at the Langchain code to see how it creates the keys and hoping the internal implementation won’t change. Alternatively, we can get the document key by calling the yield_keys function before and after the call to the embed_documents function and comparing the results. But such a solution won’t work when multiple documents are in the embed_documents call. Also, the code would look like an ugly hack.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn