
Do your clients neglect reading the documentation? Do you need to answer the same questions repeatedly even though everyone can find the answer in the documents in seconds? Does it seem familiar? I understand your pain. For more advanced techniques on finding information in large documents, check out my article on finding information in long documents with AI.
Table of Contents
- How to setup a Milvus vector database for text search
- How to upload text to Milvus vector database
- How to answer questions using GPT-3 and text embeddings
- Write a Facebook chatbot web service
- How to improve it?
Would you prefer to have a bot answer all of those questions? To answer questions using your documentation, let’s build a Facebook chatbot with GPT-3 from OpenAI and vector databases.
The task is huge. We will need to split the work into several parts:
- First, we will do the setup - connect to a database and create an empty collection.
- After that, we do data engineering. We will create text embeddings from our documentation and upload them into the vector database.
- In the third step, we need MLOps and prompt engineering. We will use the vector database and GPT-3 to retrieve the answer and a link to the relevant document.
- In the last step, we become backend engineers and build a web application with a webhook for Facebook.
In the end, we will have an AI-powered Facebook chatbot answering programming questions using articles from this blog:
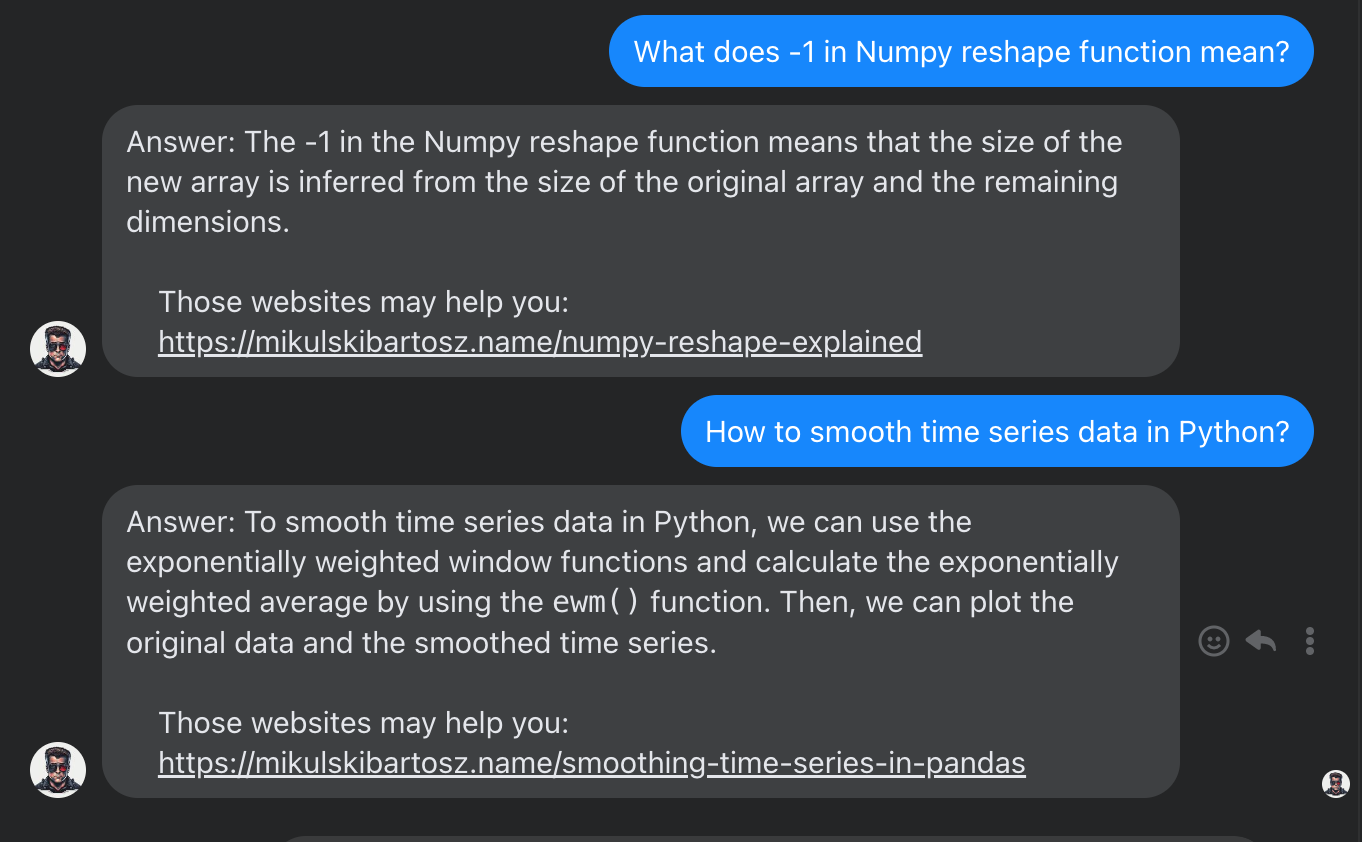
How to setup a Milvus vector database for text search
I assume you have already set up the database server and have its address. If not, look at the Getting Started guide and the administrator documentation for Milvus.
Before we start, we need to create a collection in the Milvus database and add an index for our embeddings. First, we connect to the database:
from pymilvus import (
connections,
utility,
FieldSchema,
CollectionSchema,
DataType,
Collection,
)
connections.connect("default", host="__YOUR_HOST_NAME__", port="19530")
Milvus collection and its schema
Second, we need to create a collection. The collection has a predefined schema, so we need to think about the information we want to store. For sure, we will store the embeddings. We must figure out the dimensions of the vector. From the OpenAI documentation, we know the size of embeddings — it’s a vector of 1536 numbers.
Milvus uses the concept of primary keys, so we will need a primary key too. Its value won’t matter to us; we will generate primary keys while uploading the data.
However, we would like to add a link to the relevant document when we answer a question, so we should store an URL, too. Right now, Milvus supports varchar fields for storing text values. The problem with varchar is that we need to know the maximum length of the text. I will set the varchar length to an arbitrary value. If you don’t want to worry about URL length, I suggest assigning a UUID to every article and storing the identifiers in Milvus.
When we have all of the required information, we can create the collection:
fields = [
FieldSchema(name="pk", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="url", dtype=DataType.VARCHAR, max_length=300),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=1536)
]
schema = CollectionSchema(fields, "articles with their urls")
article_collection = Collection("articles", schema)
Milvus collection index
We can’t run a quick text search in the embedding collection unless we create an index. Milvus supports multiple index types. Check the documentation to determine which index you need.
Here is an example index creation code:
index_params = {
"metric_type":"L2",
"index_type":"IVF_FLAT",
"params":{"nlist":32}
}
article_collection.create_index(
field_name="embeddings",
index_params=index_params
)
How to upload text to Milvus vector database
It’s time for data engineering now. We will preprocess the article, convert the text into vector embeddings, and upload them to the database.
Data preprocessing
I will use articles from this blog as the input text. The blog uses Jekyll to generate static pages, so all articles are in markdown files. Every file begins with a metadata section located between two lines containing ---. Additionally, in the text, we may find Jekyll template instructions. Those instructions begin with {% . We don’t need them to answer user questions, so we will remove them while preprocessing the data.
First, let’s load the article file names from the input path:
import glob
files = glob.glob(f'{INPUT_PATH}/*')
Second, we must extract the article content from each file. Let’s create a function to remove the Jekyll template operations and metadata.
def load_markdown(file_path):
with open(file_path, 'r') as data:
lines = data.readlines()
for i, line in enumerate(lines):
if line.strip() == '---' and i > 0:
content_lines = []
for content_line in lines[i+1:]:
if not content_line.startswith('{%'):
content_lines.append(content_line)
return ''.join(content_lines).strip()
We can’t eliminate all metadata because we will need the URL. The URL isn’t stored in the file. It’s part of the file name itself. We will use a regular expression to get it:
import re
def extract_url(file_path):
pattern = r'\/(?:\d{4}-\d{2}-\d{2})-(.*).md'
match = re.search(pattern, file_path)
if match:
return '/' + match.group(1)
else:
return ''
How to create embeddings from text
In the next step, we can start thinking of creating text embeddings. We will use the OpenAI Embeddings API:
import openai
# Remember to set the OpenAI API key (do NOT store it in the code)
def get_embedding(text, model="text-embedding-ada-002"):
text = text.replace("\n", " ")
return openai.Embedding.create(input = [text], model=model)['data'][0]['embedding']
Finally, we can run all those functions to get embeddings and URLs.
number_of_elements = len(files)
embeddings_with_urls = []
for i in range(number_of_elements):
file_path = files[i]
markdown = load_markdown(file_path)
url = extract_url(file_path)
embeddings = get_embedding(markdown)
embeddings_with_urls.append((url, embeddings))
Upload embeddings to the vector database
We have the URLs and embeddings but in the wrong format. Milvus expects every field separately. We must send an array of primary keys, an array of URLs, and an array of embeddings. Hence, let’s change the data structure:
primary_keys = []
urls = []
embeddings = []
for i, (article_url, article_embeddings) in enumerate(embeddings_with_urls):
primary_keys.append(i)
urls.append(article_url)
embeddings.append(article_embeddings)
Now, we can insert the data into our vector database:
article_collection.insert([primary_keys, urls, embeddings])
How to answer questions using GPT-3 and text embeddings
Let’s switch our role to MLOps engineer and write the code around AI. I have the following idea:
- Whenever we receive a message, we search for the answer in our vector database.
- We retrieve the top 3 articles and pass their content to GPT-3 to summarize.
- We take those three summaries and pass them to GPT-3 again to produce the final answer.
- We return the final answer with the links to articles used to produce it.
How to search for relevant text in a vector database
We start with the question received from the user. First, we pass the question to the get_embeddings function to generate a search vector. Second, we use the query vector to find the top 3 most relevant articles. Our function will return article URLs.
Every search requires the metric type and the nprobe parameter. Look at the article linked below to learn more about setting nprobe.
When searching using indexes, the first step is to find a certain number of buckets closest to the target vector and the second step is to find the most similar k vectors from the buckets by vector distance. nprobe is the number of buckets in step one.
You will need to call load before you search in a collection: article_collection.load().
def find_articles(question):
query_embeddings = get_embedding(question)
search_params = {"metric_type": "L2", "params": {"nprobe": 10}, "offset": 0}
results = article_collection.search(
data=[query_embeddings],
anns_field="embeddings",
param=search_params,
limit=3,
output_fields=['url'], # we retrieve also the URL field!
expr=None,
consistency_level="Strong"
)
for result in results[0]:
yield result.entity.get('url')
How to prompt GPT-3 to answer a question using the provided text
We will read the content of each retrieved article and pass the text to GPT-3. The AI model will answer the question using the article content or tell us the question cannot be answered using the provided data.
Let’s do the prompt engineering and write a function to query GPT-3. I must instruct GPT-3 to say, “I don’t know.” Otherwise, GPT-3 would try to answer the question using the knowledge from its training dataset, or it would make up a fake answer.
def summarize_article(question, markdown):
prompt = f"""Question: {question}
Article:
{markdown}
###
Does the given article contain all information required to answer the question? If not, return "Answer: I don't know."
If the article contains the answer, answer the question using the given article.
Don't use your own knowledge. If the answer is not in the provided article text, return "Answer: I don't know."
Examples:
---
Answer: I don't know.
---
---
Answer: here is the answer (one or two paragraphs)
---
"""
response = openai.Completion.create(model="text-davinci-003", prompt=prompt, temperature=0, max_tokens=200)
return response['choices'][0]['text']
When we have the prompt function, we need to load the article content again (right now, we have only the URL), pass the text to the answer function, and determine whether we received an answer:
def get_answer_candidates(question, candidate_urls):
for url in candidate_urls:
article_path = [file for file in files if url[1:] in file][0]
markdown = load_markdown(article_path)
markdown = markdown[0:3500] # GPT-3 has a token limit around 4k tokens
summary = summarize_article(question, markdown)
if "Answer: I don't know." not in summary:
yield (url, summary)
We pass the answer candidates to GPT-3 and get the final answer. We will also include the URLs of candidate articles:
def get_final_answer(question, summaries):
answers = "\n".join(summaries)
prompt = f"""Question: {question}
Answers: {answers}
###
Write a final answer to the question using the answers provided above.
If the answer is not in the provided answers, return "Answer: I don't know."
If the provided answer does not answer the question, skip it.
"""
response = openai.Completion.create(model="text-davinci-003", prompt=prompt, temperature=0, max_tokens=200)
return response['choices'][0]['text']
def answer(question):
article_candidates = find_articles(question)
urls_with_answers = list(get_answer_candidates(question, article_candidates))
urls = ["https://mikulskibartosz.name" + url for url, _ in urls_with_answers] # put your website domain here
summaries = [answer for _, answer in urls_with_answers]
final_answer = get_final_answer(question, summaries)
return final_answer, urls
Write a Facebook chatbot web service
Let’s deliver the content to the users. We will build a web service using the Flask framework. As the Facebook setup changes frequently, I will focus on the Python part of the task. You can find the current way of connecting a backend service to the Messanger API in the Facebook documentation and this tutorial.
When you setup a backend service as a webhook for Facebook, you will need to handle a verification request. You have to check if you received the correct verification token and reply to the request:
from flask import Flask, request
import requests
app = Flask(__name__)
@app.route('/', methods=['GET'])
def verify():
if request.args.get("hub.mode") == "subscribe" and request.args.get("hub.challenge"):
if not request.args.get("hub.verify_token") == VERIFY_TOKEN:
return "Verification token mismatch", 403
return request.args.get("hub.challenge"), 200
return "Hello world", 200
Now, we can receive and send messages. We will need the messages API URL with the access token to send a message. You will get the access token while setting up the service on Facebook.
API = "https://graph.facebook.com/v15.0/me/messages?access_token="+ACCESS_TOKEN
Whenever someone sends a message to a Facebook chat, our webhook receives a POST request. To reply, we send a POST request to the API URL:
@app.route("/", methods=['POST'])
def fbwebhook():
data = request.get_json()
message = data['entry'][0]['messaging'][0]['message']
the_answer, urls = answer(message['text']) # this is the GPT-3 answer function we created earlier
urls = "\n".join(urls)
response = f"""{the_answer}
Those websites may help you:
{urls}
"""
sender_id = data['entry'][0]['messaging'][0]['sender']['id']
request_body = {
"recipient": {
"id": sender_id
},
"message": {
"text": response
}
}
response = requests.post(API, json=request_body).json()
return response
Let’s run the application and start talking with our chatbot:
if __name__ == '__main__':
app.run()
How to improve it?
Sometimes, the top 3 articles are too much, and GPT-3 tries to use them all even when it makes no sense.
Perhaps, I would get a better result if I retrieved the top article first, asked GPT-3 to answer the question, retrieved the second article, and asked GPT-3 if the new data could improve the answer. If yes, I would ask GPT-3 to update the answer. Next, I would retrieve the third article and repeat the answer improvement attempt.
Of course, such an implementation would be more expensive to run, as it requires more calls to the OpenAI API, but we would avoid overzealous attempts to use all provided answer candidates in the response.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn