
PydanticAI is an AI client library for generating structured, validated output from Large Language Models (LLMs) using Python type hints and Pydantic models. By defining the expected response structure as a Python dataclass, PydanticAI automatically prompts the LLM to format its output accordingly and validates the response against the specified schema. Such output handling is particularly valuable in RAG applications where you need consistent, type-safe outputs that can be directly integrated into your application’s data structures, effectively eliminating manual parsing and reducing the risk of run-time errors due to malformed responses.
Table of Contents
- What Are We Going to Build?
- Data Preparation
- Searching for Recipes by Ingredients
- RAG with Structured Output using PydanticAI
- Logging and Observability with Logfire
- The Advantages of Structured Outputs
- Is PydanticAI the Only Tool for Structured Outputs?
PydanticAI is yet another part of the Pydantic ecosystem. As such, PydanticAI offers seamless integration with Logfire, an observability platform from the Pydantic team. The integration provides out-of-the-box monitoring of all LLM requests, tool interactions, and other application parts instrumented with Logfire (data access, REST API, etc.).
What Are We Going to Build?
If you want to learn more about different indexing methods for RAG before diving into PydanticAI, I have a separate article comparing LlamaIndex options.
We will build the RAG part of the chatbot to help users find the recipe they can cook. The user will specify a list of food they have in the fridge and ask the LLM to suggest recipes. The tool should recommend a recipe that doesn’t require additional ingredients, but if it’s not possible, the chatbot should suggest a recipe that requires the least number of extra ingredients and give the user a shopping list.
Data Preparation
We will use the RecipeNLG dataset presented in the RecipeNLG: A Cooking Recipes Dataset for Semi-Structured Text Generation paper by the researchers from the Poznan University of Technology. The dataset is available on Kaggle.
import pandas as pd
recipes = pd.read_csv('recipes.csv')
After loading the dataset into a Pandas DataFrame, we see the following columns:
- title - the title of the recipe
- ingredients - the list of ingredients required for the recipe and the quantities
- directions - the cooking directions for the recipe
- link - the link to the recipe
- source - the source of the recipe
- NER - the names of the ingredients in the recipe
The NER column is handy because it gives us unified names. For example, the ingredients “1/2 cup of milk”, “a bottle of milk,” and “milk” all refer to the same ingredient, so in the NER column, they are all called “milk.”
We will use the NER column to filter the dataset and find the recipes the user can cook with the ingredients they already have. However, we also need the ingredients column to get the exact quantities of the ingredients. And, of course, we need the title and the directions.
Storing Recipes in a Relational Database
We should define a relational database schema where we store individual ingredients (the ones from the NER column) in a single table, the recipes in another table, and the connections (ingredients required for a particular recipe) in a third table. However, for the sake of simplicity, we will use a single table for everything. After all, this article is about PydanticAI, not databases.
We will use the sqlite database, but the same approach works with any other database.
import sqlite3
conn = sqlite3.connect('recipes.db')
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS recipes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
title TEXT NOT NULL,
ingredients TEXT,
directions TEXT,
ner TEXT
)
''')
conn.commit()
conn.close()
The dataset contains JSON-parsable text. Therefore, we will parse the remaining columns and store their content as separate lines in the corresponding DataFrame columns.
import json
conn = sqlite3.connect('recipes.db')
cursor = conn.cursor()
for index, row in recipes.iterrows():
ingredients = '\n'.join(json.loads(row['ingredients'])) if pd.notna(row['ingredients']) and isinstance(json.loads(row['ingredients']), list) else ''
directions = '\n'.join(json.loads(row['directions'])) if pd.notna(row['directions']) and isinstance(json.loads(row['directions']), list) else ''
ner = '\n'.join(json.loads(row['NER'])) if pd.notna(row['NER']) and isinstance(json.loads(row['NER']), list) else ''
cursor.execute('''
INSERT INTO recipes (title, ingredients, directions, ner)
VALUES (?, ?, ?, ?)
''', (row['title'], ingredients, directions, ner))
conn.commit()
conn.close()
Searching for Recipes by Ingredients
The search function (here called: find_recipes_by_ingredients) is the most critical part of our application. The function accepts a list of available ingredients as the parameter and goes through several steps to find the best recipes:
- First, it finds the ingredients that require at least one of the ingredients from the user’s list.
- Then, the function calculates the percentage of the required ingredients the user has.
- For each recipe, the missing ingredients are added to a separate column.
- The results are sorted by the percentage of matched ingredients, and the top recipes are returned.
- Finally, the function returns the result as a Markdown table.
The database query is extracted to a separate function and wrapped in a Logfire span. The Logfile span allows us to monitor the database queries and see how many recipes are being retrieved and how long it takes. Also, if the application is too slow, we can identify whether the database query or the LLM call is the bottleneck.
import logfire
def search_in_db(available_ingredients):
with logfire.span('Retrieving recipes with ingredients {ings}', ings=available_ingredients):
conn = sqlite3.connect('recipes.db')
cursor = conn.cursor()
placeholders = ', '.join(['?'] * len(available_ingredients))
query = f"SELECT title, ingredients, directions, ner FROM recipes WHERE ner LIKE '%' || ? || '%'"
if len(available_ingredients) > 1:
additional_bindings = " OR ner LIKE '%' || ? || '%'" * (len(available_ingredients) - 1)
query = f"SELECT title, ingredients, directions, ner FROM recipes WHERE ner LIKE '%' || ? || '%'" + additional_bindings
cursor.execute(query, available_ingredients)
results = cursor.fetchall()
conn.close()
return results
def find_recipes_by_ingredients(available_ingredients, max_recipes=5):
results = search_in_db(available_ingredients)
if not results:
return "No recipes found for the given ingredients."
data = []
for title, ingredients, directions, ner in results:
recipe_ingredients = ner.split('\n')
matched_ingredients_count = sum(1 for ingredient in recipe_ingredients if ingredient in available_ingredients)
percentage = (matched_ingredients_count / len(recipe_ingredients)) * 100.0
missing_ingredients = [ingredient for ingredient in recipe_ingredients if ingredient not in available_ingredients]
data.append([title, ingredients, directions, ner, percentage, "\n".join(missing_ingredients)])
df = pd.DataFrame(data, columns=['Title', 'Ingredients', 'Directions', 'NER', 'Match Percentage', 'Missing ingredients'])
df = df.sort_values('Match Percentage', ascending=False)
df = df.head(max_recipes)
return df.to_markdown()
RAG with Structured Output using PydanticAI
Finally, we can start defining the RAG. Before we start, we have to prepare Python dataclasses for the structured output. I want a recommendation, a list of recipes, and a shopping list if anything is missing, so the dataclass will look as follows:
from typing import List
from dataclasses import dataclass
@dataclass
class Recipe:
title: str
ingredients: str
directions: str
@dataclass
class Answer:
recommendation: str
shopping_list: List[str]
best_recipes: List[Recipe]
In the next step, we define the PydanticAI Agent. The Agent class encapsulates the LLM connection and interactions with the tools we provide. When we define the Agent, we must specify the response type (string is default if we don’t specify anything) and the system prompt if we don’t want to explain the task in every user’s prompt.
from pydantic_ai import Agent
# make sure that you have the OPENAI_API_KEY environment variable set!
agent = Agent(
'openai:gpt-4o-mini',
system_prompt="""You help the user decide what to cook with the ingredients they already have.
In the response, you return your recommendation and the recipes that don't require buying anything.
If the user doesn't have enough ingredients to cook anything, you choose one recipe with the shortest list of missing ingredients and return it as the recommendation together with the shopping list.""",
result_type=Answer
)
Next, we add a tool to the Agent using the Python decorator. The agent part of the name comes from the variable name. We use tool_plain because our tool doesn’t need access to the PydanticAI context.
The tool’s name, parameters (names and types), and the doc-string will be used to generate the prompt for the LLM. If your model misuses a tool or doesn’t choose the right one, tweak the doc-string to explain the expected behavior better.
@agent.tool_plain
def find_recipes(available_ingredients: List[str]) -> str:
"""Search for the recipes that can be cooked with the ingredients the user has.
Accepts a list of the ingredients the user has as nouns.
For example: If the user says "3 eggs, a can of milk, and bag vanilla wafers", the input would be ["eggs", "milk", "vanilla wafers"].
Returns a markdown table with the title, detailed ingredients (ingredients column), directions, ingredient names (NER column), match percentage (% of ingredient that the user has), and missing ingredients (what the user has to buy)."""
return find_recipes_by_ingredients(available_ingredients)
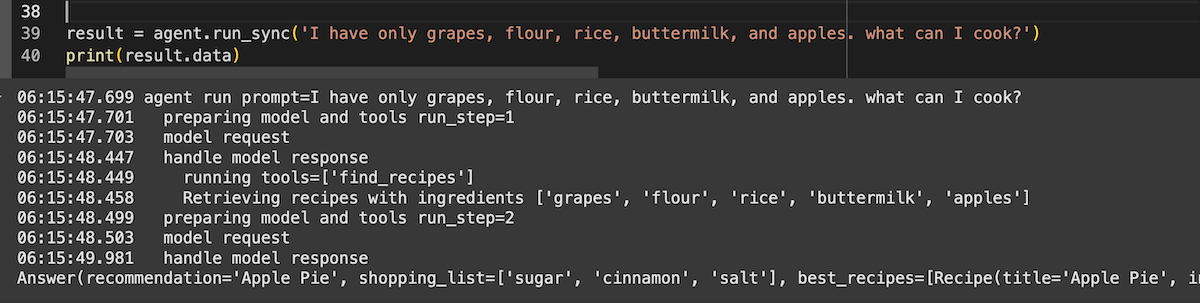
The agent is ready to use. When we pass the user’s question to the run_sync method, PydanticAI sends the prompt to the LLM, runs the tools, and returns the answer as an instance of the expected dataclass.
result = agent.run_sync('I have only grapes, flour, rice, buttermilk, and apples. what can I cook?')
print(result.data)
Logging and Observability with Logfire
If we configure Logfire, all PydanticAI requests will be logged and visible in the Logfire UI.
import logfire
# the following line requires an environment variable LOGFIRE_TOKEN to be set!
logfire.configure()

In the picture, we see two model requests. In the first one, the model chooses which tool to run and with which parameters. In the second one, the model returned the answer. Between the two requests, we see the tool response and (inside of it) our Logfile span block from the data reading function.
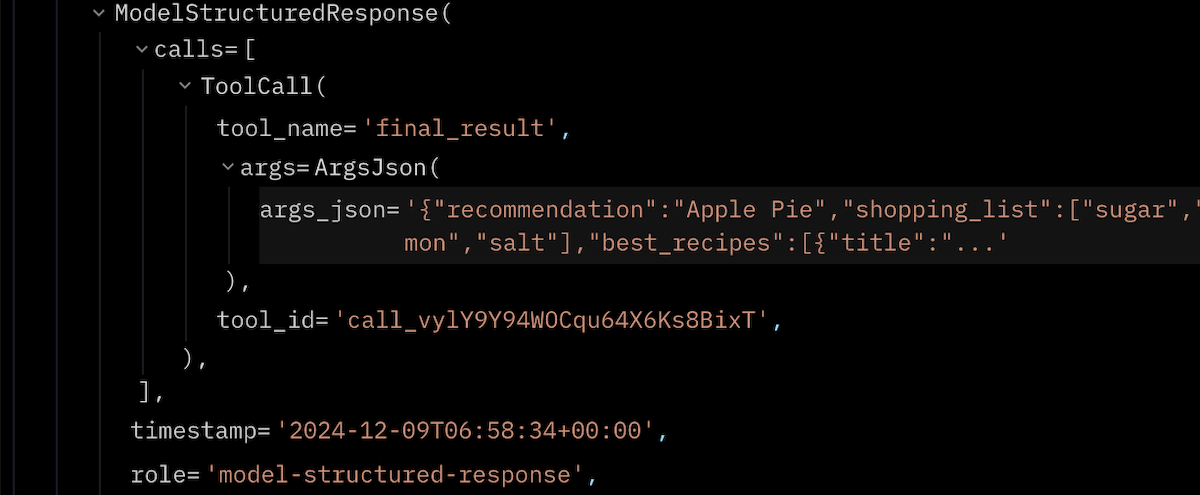
Additionally, we can notice the internal trick of the PydanticAI library. The LLM is forced to output the answer in the specified format not by explaining the format in the prompt but by creating a specialized tool called final_result. The tool accepts the same arguments as the fields of our response data model.
The Advantages of Structured Outputs
Using structured outputs through tools like PydanticAI offers several advantages over free-form or JSON-parsable text responses.
First, structured outputs provide reliable type safety and validation, eliminating the common issues of malformed JSON responses or inconsistent data structures that often occur even when explicitly requesting JSON in the prompt.
Second, structured outputs integrate seamlessly with your application’s data structures and type system, allowing direct use of the LLM’s responses without additional parsing or error-handling code.
Finally, as demonstrated by tools like Logfire integration, structured outputs enable better observability and monitoring of your AI system, making it easier to track performance, debug issues, and ensure the reliability of your RAG application in production.
Is PydanticAI the Only Tool for Structured Outputs?
Of course not. We have tons of options to choose from. For example:
- the Instructor library
-
with_structured_outputmethod in Langchain -
response_formatandchat.completions.parsein the official OpenAI Python client
Just choose one and use structured outputs.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn