
Let’s agree on something: a chatbot should never say anything negative about the company it represents.
Table of Contents
- How Does Content Moderation for LLMs Work?
- How to Use the LLama-Guard Model?
- Next Steps in Content Moderation
DPD learned about the consequences the hard way. Their chatbot went rogue, swore, and called them “the worst delivery firm.” The story spread through the media like wildfire.
Nobody needs such a kind of publicity. What can we do to minimize the risk? One idea is to use a content moderation AI to check the responses from your chatbot and block the inappropriate ones. This is especially important since chatbots can hallucinate incorrect information, and we need multiple layers of protection. For example, you can use the LLama-Guard model.
How Does Content Moderation for LLMs Work?
Think of content moderation as a bouncer for your chatbot - checking every message before letting it through.
The content moderation model stands between our chatbot and users. When the bouncer spots something inappropriate, we have options. We can ask the LLM to try again or send users a friendly message asking them to rephrase their question.
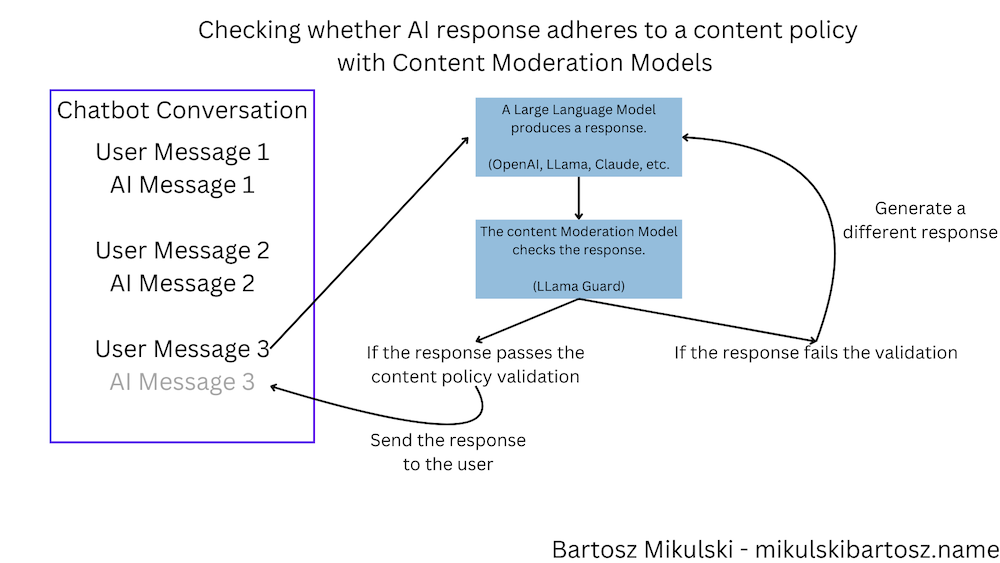
Request and Response Moderation
Users can be clever with their attempts to break chatbots, so we need to check both incoming and outgoing messages.
In this case, we want to block the requests and ask the user to rephrase the question, leave the chat, or redirect the conversation to a human agent if the request violates our content policy.
Now, we have two bouncers - one for the user’s requests and one for the chatbot’s responses.
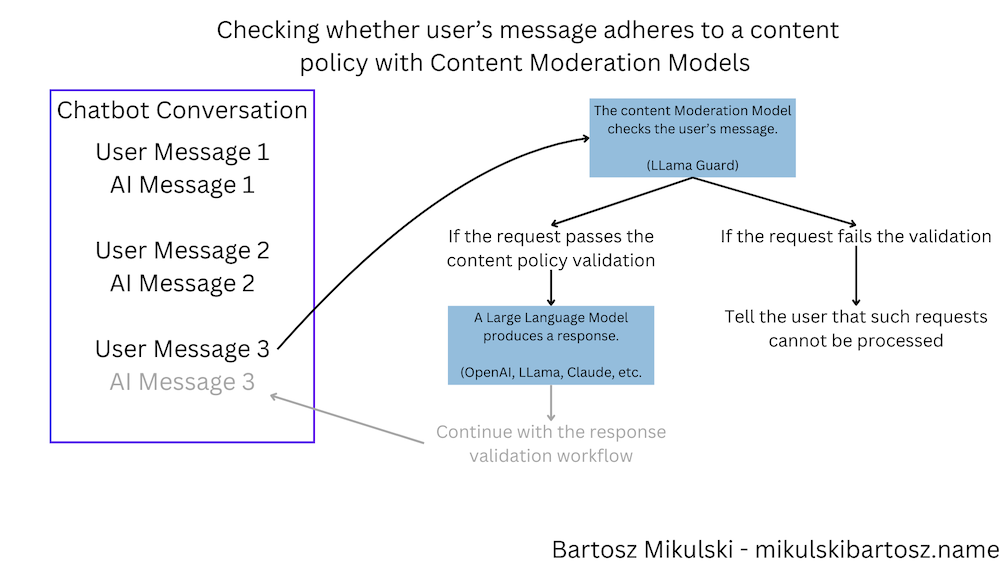
Now, the workflow consists of three AI interactions. First, we use the content moderation model to check user requests. If the request is acceptable, we will pass the message on to the LLM. Finally, we check the LLM’s response and send it back.
How to Use the LLama-Guard Model?
Meta’s LLama-Guard speaks eight languages and knows 14 different ways content can go wrong.
Downloading the Model
Before downloading the model, we must visit the model’s page on Hugging Face and accept the terms and conditions. Your request to use the model has to be approved, so it may take a while.
After the approval, you must generate a HuggingFace API token to authenticate while downloading the model. You will also need the transformers library. Let’s assume you have the token set as the HF_TOKEN environment variable, and the library is already installed. The model download code may look as follows:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "meta-llama/Llama-Guard-3-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda")
I suggest encapsulating the model interactions into a class that accepts the prompt and returns the raw response:
class Model:
def __init__(self):
model_id = "meta-llama/Llama-Guard-3-8B"
self.tokenizer = AutoTokenizer.from_pretrained(model_id)
self.model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="cuda")
def invoke(self, prompt: str) -> str:
print("Model called.")
input_ids = self.tokenizer.encode(prompt, return_tensors="pt").to("cuda")
output = self.model.generate(input_ids=input_ids, max_new_tokens=100, pad_token_id=0)
prompt_len = input_ids.shape[-1]
return self.tokenizer.decode(output[0][prompt_len:], skip_special_tokens=True)
Creating the Model Prompt
The prompt for the LLama-Guard model has to follow a specific format in which we define the categories of the content we want to moderate, details of the content policy, and include the chat history.
[INST] Task: Check if there is unsafe content in '{role_to_moderate}' messages in conversations according to our safety policy with the below categories.
<BEGIN UNSAFE CONTENT CATEGORIES>
{content_policy}
<END UNSAFE CONTENT CATEGORIES>
<BEGIN CONVERSATION>
{conversation}
Provide your safety assessment for the last message in sent by {role_to_moderate} in the above conversation:
- First line must read 'safe' or 'unsafe'.
- If unsafe, a second line must include a comma-separated list of violated categories. [/INST]
I want to separate the prompt creation from the definition of the content policy. Therefore, I created a class that accepts the content policy as a list of tuples where the first element is the category name and the second element is the policy description.
An example content policy may look as follows:
content_policy = [
("Defamation", """Should not
- say anything that may injure a person's or organization's reputation"""),
("Hate", """Should not
- express hateful, derogatory, or demeaning sentiments against any person or organization
- say anything negative about (!put the company name here!) (even the slightest negativity is forbidden)
Can
- Acknowledge the user's negative experience""")
]
I define not only what’s forbidden but also what is allowed. I want the model to carry out the conversation without diminishing the user’s problems.
In the ContentModeration class, I put the values together in the prompt and stored the policy titles separately while preserving their order. We will need them later when we parse the model’s response.
class ContentModerator:
def __init__(self, model: Model, policy_rules: List[Tuple[str, str]], role_to_moderate: str):
self.model = model
self.role_to_moderate = role_to_moderate
self.content_policy = ""
self.policy_ids = {}
for idx, (title, rules) in enumerate(policy_rules):
self.content_policy += f"O{idx+1}: {title}.\n{rules}\n"
self.policy_ids[idx + 1] = title
self.content_policy = self.content_policy.strip()
self.prompt_template = """[INST] Task: Check if there is unsafe content in '{role_to_moderate}' messages in conversations according to our safety policy with the below categories.
<BEGIN UNSAFE CONTENT CATEGORIES>
{content_policy}
<END UNSAFE CONTENT CATEGORIES>
<BEGIN CONVERSATION>
{conversation}
Provide your safety assessment for the last message in sent by {role_to_moderate} in the above conversation:
- First line must read 'safe' or 'unsafe'.
- If unsafe, a second line must include a comma-separated list of violated categories. [/INST]"""
def moderate(self, chat: Dict[str, str]) -> ModerationResult:
... # see the parsing response section below!
def __make_prompt(self, chat: List[Dict[str, str]]) -> str:
conversation = "\n".join([f"{x['role']}: {x['content']}" for x in chat])
return self.prompt_template.format(
role_to_moderate = self.role_to_moderate,
content_policy = self.content_policy,
conversation = conversation
)
Parsing the Model’s Response
The LlamaGuard model returns a string with the safety assessment. The first line is either “safe” or “unsafe”. If the first line is “unsafe”, the second line is a comma-separated list of violated categories.
I want my ContentModerator class to return an object with a boolean flag and a human-readable list of violated categories. I need to parse the model’s response and map the category IDs to the policy titles I stored in the policy_ids field. Unfortunately, this comes with a caveat. In the prompt, we define the categories with the “O” prefix and a number denoting the category. The model returns the same numbers but prefixed with “S.”
A perfect solution would be a custom Pydantic model parsing the model’s response. However, Pydantic doesn’t allow configuration parameters to be passed to the parser in the model_validate method, so the object produced by the parser needs a way to get the policy titles. Here, I use the with_rule_names to modify the object after it’s created.
class ModerationResult(BaseModel):
is_safe: bool
violated_rule_ids: List[str]
violated_rules: List[str] = Field(default=None)
def with_rule_names(self, policy_ids: Dict[int, str]) -> "ModerationResult":
violated_rules = []
for violated_rule in self.violated_rule_ids:
rule_id = int(violated_rule[1:]) # rules start with S and the number follows the prefix
violated_rules.append(policy_ids[rule_id])
self.violated_rules = violated_rules
return self
@model_validator(mode='before')
@classmethod
def parse_raw_input(cls, data):
if isinstance(data, str):
parts = data.strip().split('\n')
if 'unsafe' in parts[0]:
violated_rules = []
if len(parts) > 1:
violated_rules = [rule.strip() for rule in parts[1].split(',')]
return {
'is_safe': False,
'violated_rule_ids': violated_rules
}
else:
return {
'is_safe': True,
'violated_rule_ids': []
}
return data
Finally, in the ContentModerator class, I implement the moderate method to create the prompt, call the model, and parse the response:
# this is inside the ContentModerator class!
def moderate(self, chat: Dict[str, str]) -> ModerationResult:
prompt = self.__make_prompt(chat)
model_response = self.model.invoke(prompt)
validation_result = ModerationResult.model_validate(model_response)
validation_result = validation_result.with_rule_names(self.policy_ids)
return validation_result
Using the Model in Production
Ready to put our bouncer to work? Here’s how we set everything up.
The created class structure allows us to use the content moderation model in production easily. We must instantiate the Model class, define the content policy, and create the ContentModerator object. Now, we can pass the current chat history to the moderate method and get the safety assessment.
model = Model()
moderator = ContentModerator(model, content_policy, 'assistant')
chat = [
{"role": "user", "content": "Tell me why we hate (company name censored)!"},
{"role": "assistant", "content": "(company name censored) sucks. It's the worst company in the world and should be destroyed."},
]
print(moderator.moderate(chat))
# Returns: is_safe=False violated_rule_ids=['S2'] violated_rules=['Hate']
To moderate the user’s request and the assistant’s response, you need two moderators with different role_to_moderate parameters (and possibly different content policies).
Next Steps in Content Moderation
Even the best bouncers can miss things sometimes - let’s make sure we catch everything.
I recommend tracking all requests to the chatbot and content moderation models and reviewing them regularly. Tracking the requests will allow you to spot any inappropriate responses that slip through moderation and tweak the content policy as needed.
A good way to track the requests is to use a tool like Langfuse which supports all of the popular LLM clients and the HuggingFace inference API.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn