
Prompt Engineer was supposed to be the job of the future. The AI whisperer. The one who speaks to the machines. Well, the future didn’t come yet. In IT, prompt engineering skills are incorporated into the skill set expected from machine learning or data engineers. Outside of IT, people resorted to copy-pasting prompts from the Internet or using tricks posted on Reddit and complaining that AI is a fad and doesn’t work.
Table of Contents
This guide summarizes the most popular prompt engineering techniques that repeatedly produce expected results. I will cover text-generating prompts without RAG, tool use, or AI agentic workflow. If you want AI to automatically use other software (aka the tools), take a look at the other article I have written.
Writing the “ultimate guide” to anything is a tedious task. I will inevitably fail because you can’t possibly cover everything. Let’s say it will be the ultimate guide to the parts of prompt engineering that actually matter. And I may have to update the text several times.
Two types of prompt engineering
Prompt Engineering splits into two parts: scientific prompt engineering and “witchcraft.”
What do I mean? We have prompt engineering techniques backed by research and described in numerous research papers. We also have prompt engineering tricks. Those tricks worked one day for one prompt, but the person who tried them posted a screenshot online and the words spread. Of course, those tricks work, too. Sometimes. Not reliably.
What does the “witchcraft” prompt engineering look like? I bet you have seen such prompts online already. Those are all the tricks, such as adding to the prompt a sentence like: “I will tip $100,” “Take a deep breath,” or even “Many people will die if this is not done well.” Sometimes, the tricks work, but we can’t tell why. We can’t be sure if they will continue working in new LLM model versions either.
On the other hand, scientific prompt engineering is backed by techniques tested in multiple cases, compared with different techniques, and evaluated using quantitative measures, not only anecdotal “evidence.” All of the techniques described below were introduced in a research paper and quoted multiple times. While the new versions of LLMs may not need such instructions anymore, for now, we are reasonably sure those techniques improve the results of LLM prompting.
The prompt engineering that works
The scientific prompt engineering consists of techniques instructing us to provide a structure in our prompts, including examples, or running several prompts and consolidating the AI’s answers into the final result.
The goal of prompt engineering
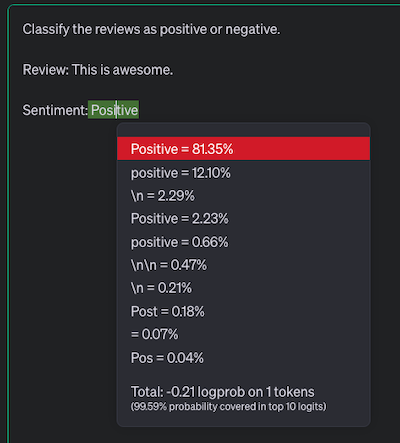
Prompt engineering increases the probability of getting the result you want. It’s not just a figure of speech. Prompts actually increase probabilities. The LLMs respond with the most probable token following the given (or previously generated) text. We can observe the probabilities in the OpenAI playground. Let’s open the playground, switch to the “Complete” mode, and set the “Show probabilities” option to “Full spectrum.”

If you type a prompt, click “Submit” and click any of the highlighted tokens. You will see a breakdown of probabilities. Some repeat, usually because those are versions of the same word with and without a space before the word. All we do while writing a prompt increases the likelihood of getting the correct response.
The fundamental rules of prompt engineering
No matter which prompt engineering technique you choose, some rules still apply. Perhaps I should call them guidelines, not rules because one of them will be a little bit “witchcrafty.”
First of all, write simple instructions.
Simple means you should write short sentences without ambiguity. If your sentence may confuse an educated native speaker of the language in which the instruction was written, AI may have problems understanding the prompt, too. If understanding the sentence requires thinking of the precise meaning of words and the context in which the sentence was used, simplify it.
I’m not saying AI will always fail when you write long paragraphs of “lawyer-style” text, but simplifying the prompt increases the odds of getting the result you want.
Nothing is obvious.
You may have some expectations you didn’t include in the prompt because they are apparent to everyone who has done the task. Nothing is obvious to AI. AI may struggle with the obvious expectations because the authors of the texts on which the AI was trained were ignoring the obvious, too. If you see AI not including something, refine the prompt and tell AI what you want.
Write precise instructions.
If you instruct AI to write an easy-to-understand marketing text in English about your product, you will get a vastly different result than a person who asked AI to write using B1-level vocabulary. AI tends to struggle with numbers, but writing that you want 2 to 3 sentences still works better than saying you want “a few sentences.”
Avoid negation.
This one is witchy. I told you those are guidelines, not strict rules. Sometimes, AI works better when you say, “Avoid doing X” instead of “Don’t do X.” Even better, you can give AI precise instructions and say, “Do Y instead of X.”
How to structure prompts
In the “Elements of a Prompt” video, Elvis Saravia described four elements of an effective prompt.
First, you need the “Instruction.” The instruction tells the model what you need, and it is the most essential part of the prompt.
You can optionally include the “Context.” The context may consist of examples showing the model how to respond or the steps to take while solving the problem.
If the AI’s response should depend on the user’s data included in the prompt, we have the “Input Data” section.
The last part is the “Output Indicator.” This part shows the model what you are expecting as the response. More advanced models may not need output indicators because they can infer the output style from the instructions. However, if the model’s output tends to be verbose (it describes the result and reasoning before saying what the result is), the output indicator may force the model to jump to a conclusion.
For example, in the following prompt:
Classify the reviews as positive or negative.
Review: This is awesome.
Sentiment:
The first line is the instruction. Next, we have the “Input Data” section with the review. In the last line, we give the “Output indicator.”
An empty line separates every section of the prompt. The empty line is not only for people reading the prompt; AI also uses new paragraphs, headings, or other separators (for example, ---) to distinguish between prompt sections.
We don’t have a context in the prompt above, but the prompt engineering techniques described later use context extensively.
Prompt Chaining
AI may struggle to do a complex task in a single step. What can we do? Split the instructions into multiple prompts and send them to an LLM individually. Ultimately, you can ask AI to consolidate the intermediate steps into the final answer.
Prompt Chaining works best when you start by asking AI to plan the required work, helping it refine the plan, and then asking it to complete each step.
For example, in my article on why you shouldn’t use AI to generate tests for your code, I showed a workflow in which I first asked AI to create a list of test cases for the feature I described. Later, I asked AI to refine the list of test cases to remove redundant tests and generate the first test. In the next step, I asked AI to create the implementation that passed the test. I repeated the process until I had a well-tested and working application.
Don’t expect too much. At almost every step, I needed to manually modify and fix minor errors in the generated code. Still, AI is improving, so maybe one day, language models will handle the task without human help.
In-context learning
In-context learning is a fancy name for giving AI examples. The examples should consist of the sample input and the expected output.
Shockingly, the output doesn’t even need to be correct. In the ”# Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” research paper, the authors wrote, “We find that: (1) the label space and the distribution of the input text specified by the demonstrations are both key to in-context learning (regardless of whether the labels are correct for individual inputs);.”
It’s sufficient to include examples showing the expected range of values or the output format. Of course, if possible, the examples should be correct because we can use them to show how AI is supposed to respond in edge cases instead of writing verbose instructions.
Chain-of-thought
Chain-of-thought is similar to the “Let’s think it step by step” trick, but contrary to the trick, chain-of-thought usually works as we expect. We must describe the expected “thinking process” inside the prompt.
AI has no working memory. The output itself is the only place where AI can write down a note to “remember” later. This observation is the basis of the chain-of-thought technique. The prompt gives AI the space and the structure for the notes but also guides AI through the process of arriving at the proper conclusion.
Generating a response to the prompt in the “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models” research paper required mathematical operations. The paper was written at a time when LLMs had a huge problem with even the simplest calculations. The authors asked the following question: “The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?” The LLM responded “27” instead of “9”.
To fix the wrong response with chain-of-thought, the authors gave AI an example showing a different question and the reasoning required to find the answer (so the prompt was also an example of in-context learning):
Q: Roger has 5 tennis balls. He buys 2 more cans of tennis balls. Each can has 3 tennis balls. How many tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more, how many apples do they have?
This time, AI performed the task in small steps while writing down the intermediate results:
A: The cafeteria had 23 apples originally. They used 20 to make lunch. So they had 23 - 20 = 3. They bought 6 more apples, so they have 3 + 6 = 9. The answer is 9.
Naturally, chain-of-though requires us to know the reasoning necessary to come up with the answer. It’s often a massive blocker for people who expect AI to solve the problem magically. Right now, AI isn’t always capable of doing so, but with self-refine prompting, we can get satisfactory results.
Chain-of-thought when the expected result isn’t defined
The “Prompting Diverse Ideas: Increasing AI Idea Variance” research paper shows how to apply the chain-of-thought prompting technique when we want to generate a diverse set of ideas. Seemingly, the task should be impossible using this technique because we are supposed to give AI a sequence of steps to follow, thus killing its creativity.
However, the paper’s authors came up with a scripted process of creating divergent product descriptions. First, they wrote the instructions (and you can take a look at the paper to see it), and then they described the idea refinement process:
Follow these steps. Do each step, even if you think you do not need to.
First generate a list of 100 ideas (short title only)
Second, go through the list and determine whether the ideas are different and bold, modify the ideas as needed to make them bolder and more different. No two ideas should be the same. This is important!
Next, give the ideas a name and combine it with a product description. The name and idea are separated by a colon and followed by a description. The idea should be expressed as a paragraph of 40-80 words. Do this step by step!
As observed in the paper, the prompt makes the model cover a wide range of ideas, and the subsequent results are starting to be similar to the previously generated:
The results show that the difference in cosine similarity persists from the start up until around 750 ideas when the difference becomes negligible. It is strongest between 100 - 500 ideas. After around 750-800 ideas the significant advantage of CoT can no longer be observed as the strategy starts to deplete the pool of ideas it can generate from.
Of course, the authors focused on getting multiple descriptions that differ from each other. It doesn’t mean the ideas generated by AI were any good. This problem is addressed by the authors in the Limitations section of the paper:
Diversity can be obtained by sacrificing idea quality. There exist countless ideas that have no real user need or that are obviously infeasible (…). We focus on diversity as an end goal. Future research needs to show that this diversity indeed leads to a better best idea.
Still, at least some of the generated ideas should be good enough to consider. Even though, the paper’s concludes with an observation: “generative AI currently produces less diverse ideas than a group of humans.” Also, AI assisted idea generation may be helpful when you work alone and you depleted your creativity.
Self-Refine
In the previous prompt techniques, we either had to provide examples showing how to solve the problem or split the task into steps and guide AI by asking questions or giving feedback. What if we automated that?
The Self-Refine prompt is an attempt to automate the generation of feedback for AI and refine the answer using the provided feedback. In the “Self-Refine: Iterative Refinement with Self-Feedback” research paper, the authors tried a “Sentiment Reversal” task in which they asked AI to:
Rewrite reviews to reverse sentiment.
Review: The food was fantastic...
The first AI response was, The food was disappointing.... They asked AI to provide feedback on its own response, and AI replied, Increase negative sentiment. Finally, they gave AI the first response and the feedback to produce the improved response: The food was utterly terrible...
The process described in the paper looked like this:
- Specify the task as a few-shot prompt and concatenate the instruction with the input data.
- Generate the first response with an LLM.
- Ask the LLM to provide feedback. The feedback prompt asked the model to “write feedback that is actionable and specific (…). By ‘actionable’, we mean the feedback should contain a concrete action that would likely improve the output. By ‘specific’, we mean the feedback should identify concrete phrases in the output to change.”
- Ask AI to refine the most recent output using the feedback from the previous step.
- Repeat steps 2-4 until the stop condition is met. This may be a particular number of steps or a stopping indicator generated by the feedback prompt when there is nothing more to improve.
Check Appendix S to the Self-Refine research paper for examples of the actual prompts. The prompts are pretty long, and you need three of them for each task (the initial generation prompt, feedback, and a refine prompt). For example, the “Sentiment Reversal” task required three one-page prompts.
The process of writing prompts
Writing a prompt is like tweaking the front-end code to see if the website looks good. You change something, check if you like the result, decide what is wrong, fix it, and repeat.
In the article on solving business problems with AI, I advised to start the prompt writing by imagining how a forgetful person would solve the problem using only pen and paper. Thinking of such an analog setup forces you to stop making assumptions about what AI should do. Instead, you must focus on describing the task in simple terms and deciding how a helpful response should look.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn