
I have seen way too many startups selling services letting you chat with a YouTube video or a PDF for 10 USD a month. They sell those services as if they were revolutionary technology, but in reality, you can build such a service in one hour. To be fair, they spent weeks making the UI look nice, and I will use Streamlit to generate the UI, but the point still stands.
Table of Contents
- What do we need to build a chatbot for a YouTube video (or a PDF)?
- OpenAI Assistants API
- How do you create an OpenAI Assistant with a Vector Store?
- How do you upload data into the OpenAI Assistant vector store?
- How do you send a message to the OpenAI Assistant?
- Putting it all together in a Streamlit app
- Repository with the code
What do we need to build a chatbot for a YouTube video (or a PDF)?
We are building an application that looks like this:
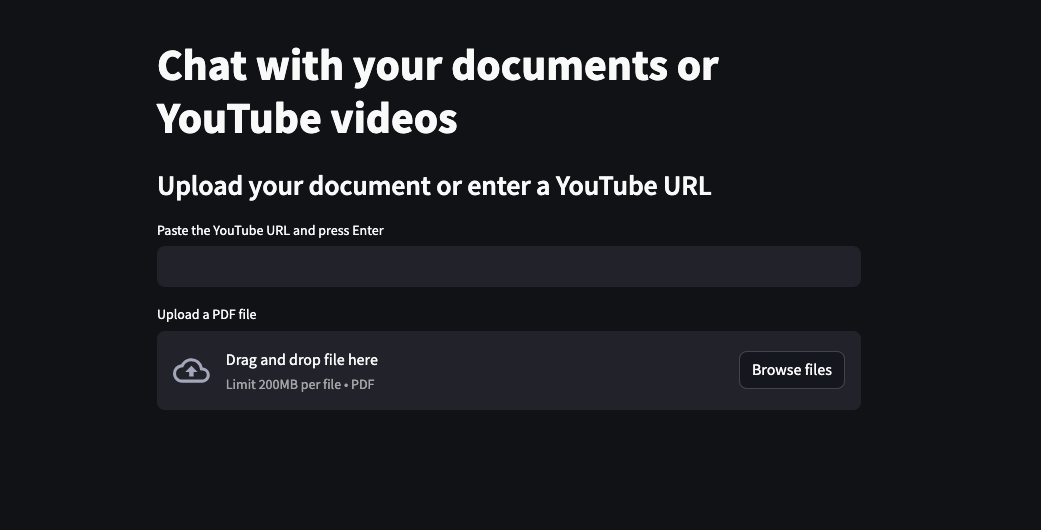

The application allows the user to upload a PDF file or paste a YouTube video link. When the user provides the data, the application uploads the file to the OpenAI Assistant Vector Store. In the example, we use the same vector store and assistant for all users. In an actual application, you should create a new assistant and vector store for each user.
When the data is ready, the user can send a message to the assistant and get a response based on the data in the vector store.
We will need only three libraries to build the application:
-
streamlitto create the UI (I used version 1.34.0) -
openaito interact with the OpenAI API (version 1.28.1) -
youtube-transcript-apito get the transcript from a YouTube video (version 0.6.2)
OpenAI Assistants API
The OpenAI Assistants API is in beta right now. I hope the API will be improved in the future, but for now, it’s a bit clunky. We will have to create a vector store and an assistant. While we create the assistant, we attach the vector store to it. Then, we upload the data into the vector store. Those parts are not too bad; the weird part of the API is handling messages.
When we want to send a message, we have to create a thread first (and that’s ok), then create a message in the thread. And nothing happens. We have to run the thread with the new messages, wait until the run finishes, and retrieve the messages from the thread. The first message in the thread is the most recent, so if you want all messages, you have to reverse the list.
Before we begin, create an instance of the API client and configure the client with your API key:
from openai import OpenAI
openai = OpenAI(api_key=openai_api_key)
How do you create an OpenAI Assistant with a Vector Store?
First, we must create a vector store. We want to have only one vector store for all users (a terrible idea in production, but good enough in a tutorial). We will iterate over all vector stores in your account and reuse an existing one if a vector store with the same name already exists.
def __create_vector_store():
vector_store_name = "the name you want"
vector_stores = openai.beta.vector_stores.list()
for vector_store in vector_stores.data:
if vector_store.name == vector_store_name:
return vector_store
vector_store = openai.beta.vector_stores.create(
name=vector_store_name
)
return vector_store
Now, we need an assistant with the file_search capability and the attached vector store. Again, we create only one and reuse the existing one if it already exists.
def __create_assistant(vector_store):
assistant_name = "the name you want"
vector_store_id = vector_store.id
all_assistants = openai.beta.assistants.list()
for assistant in all_assistants:
if assistant.name == assistant_name:
return assistant
assistant = openai.beta.assistants.create(
name=assistant_name,
tools=[{"type": "file_search"}],
model="gpt-4-turbo",
tool_resources={"file_search": {"vector_store_ids": [vector_store_id]}},
)
return assistant
How do you upload data into the OpenAI Assistant vector store?
We want two ways to upload new data into the vector store. We either accept YouTube video links or PDF files.
However, the vector store always requires a binary stream with the data, so first, we create a function to read a given file and upload it to the OpenAI vector store.
def upload_file_stream(vector_store, file_path):
file_paths = [file_path]
file_streams = [open(path, "rb") for path in file_paths]
batch = openai.beta.vector_stores.file_batches.upload_and_poll(
vector_store_id=vector_store.id, files=file_streams
)
if batch.status != "completed" or batch.file_counts.failed > 0:
raise Exception("Failed to upload file to vector store")
Now, we can reuse the upload function in two loader implementations.
First, let’s create a function to load a PDF file into the vector store. The function’s parameter is a file uploaded to Streamlit using the st.file_uploader. We will add that code later.
import tempfile
def upload_pdf_file(uploaded_file):
file_bytes = uploaded_file.getvalue()
with tempfile.NamedTemporaryFile(mode="wb", suffix=".pdf") as tmpfile:
tmpfile.write(file_bytes)
tmpfile.flush()
upload_file_stream(vector_store, tmpfile.name)
We could have done it by passing the file_bytes to the upload_file_stream function, but I wanted a single function for interactions with the vector store. Hence, the intermediate step with the temporary file.
The second loader function gets a YouTube video link and downloads the transcript using the youtube-transcript-api library. The API requires the video ID, so we extract the ID from the link. YouTubeTranscriptApi returns the transcript with timestamps. We don’t care about the timestamps, so we merge the transcript into a single string. Finally, we store the transcript in a temporary file and upload the file to the vector store.
import re
import tempfile
from youtube_transcript_api import YouTubeTranscriptApi
def upload_youtube_transcript(url, languages: List[str] = ["en"]):
video_id_match = re.search(r"(?:v=|\/)([0-9A-Za-z_-]{11})", url)
if video_id_match:
video_id = video_id_match.group(1)
else:
raise ValueError("Invalid YouTube URL")
transcript = YouTubeTranscriptApi.get_transcript(video_id, languages=languages)
full_transcript = " ".join([entry["text"] for entry in transcript])
with tempfile.NamedTemporaryFile(mode="w", suffix=".txt") as f:
f.write(full_transcript)
f.flush()
upload_file_stream(vector_store, f.name)
Before we continue, we need a way to distinguish between an assistant whose vector store contains any data and an assistant without any data. Let’s implement an is_ready function to check if the user has uploaded data.
def is_ready(vector_store):
vector_store_files = openai.beta.vector_stores.files.list(
vector_store_id=vector_store.id, limit=1
)
return len(vector_store_files.data) > 0
Finally, we can send our questions to the AI.
How do you send a message to the OpenAI Assistant?
As mentioned, the Assistant API requires creating a thread, adding a message to the thread, running the thread in an assistant’s context, and retrieving the messages from the thread. Also, the messages are returned in reverse order, so, for our purpose, it’s sufficient to get the first message (containing the AI’s response).
thread = None # The thread is a global variable
def ask(question):
if thread is None:
thread = openai.beta.threads.create()
message = openai.beta.threads.messages.create(
thread_id=thread.id, role="user", content=question
)
openai.beta.threads.runs.create_and_poll(
thread_id=thread.id, assistant_id=assistant.id
)
messages = openai.beta.threads.messages.list(thread_id=thread.id)
for message in messages.data:
for content in message.content:
message = content.text.value
return message
Putting it all together in a Streamlit app
In the Streamlit application, we will display two input fields. The first is for the YouTube video link, and the second is for the PDF file. When the user provides the data, we upload it to the vector store and display a chat window instead.
In the chat, the user can ask questions about the file and get responses from the AI.
import streamlit as st
st.title("Chat with your documents or YouTube videos")
if not is_ready():
st.subheader("Upload your document or enter a YouTube URL")
youtube_url = st.text_input("Paste the YouTube URL and press Enter", "")
uploaded_pdf = st.file_uploader("Upload a PDF file", type=["pdf"])
if youtube_url:
with st.spinner("Loading transcript..."):
upload_youtube_transcript(youtube_url)
st.success("Transcript loaded")
if uploaded_pdf:
with st.spinner("Loading PDF..."):
upload_pdf_file(uploaded_pdf)
st.success("PDF loaded")
if is_ready():
st.subheader("Ask your question")
if "messages" not in st.session_state:
st.session_state.messages = [
{"role": "assistant", "content": "How can I help you?"}
]
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
if prompt := st.chat_input(placeholder="Ask a question:"):
st.session_state.messages.append({"role": "user", "content": prompt})
st.chat_message("user").write(prompt)
with st.spinner("Thinking..."):
ai_response = ask(prompt)
st.session_state.messages.append(
{"role": "assistant", "content": ai_response}
)
st.chat_message("assistant").write(ai_response)
Repository with the code
I have created a repository with the application’s code. You can find it here. I also included code to clear the vectors store and start a new chat in the repository.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn