
“My AI evaluation costs more than development.” This complaint from engineering leaders is increasingly common. When Andrej Karpathy noted spending “1/3 of his time on data, 1/3 on evals, and 1/3 on everything else,” he validated what many teams experience: evaluation is consuming disproportionate resources.
Table of Contents
- Why Your AI Evaluation Costs Are Spiraling Out of Control
- Tiered Evaluation Approaches: Test Broadly, Then Dive Deep
- Shorten the Prompts. Save Money in Eval and in Production
- Sources
The math is brutal—cloud-based LLMs charge per token, complex workflows require multiple calls per test case, and costs scale linearly with dataset size. A standard evaluation suite with 1,000 examples can silently drain thousands from your budget each iteration.
Stop the bleeding. The research-backed techniques in this guide have helped engineering teams reduce evaluation costs while maintaining the statistical significance needed for production systems. As one referenced paper says, “minimal sampling rate of 1% proves effective for benchmarks like MMLU.” That’s a 99% improvement!
Why Your AI Evaluation Costs Are Spiraling Out of Control
Unlike traditional software testing, where running additional test cases has minimal marginal cost, every AI evaluation instance incurs API charges. Everything you do multiplies the cost:
Cost = (Dataset Size) × (Test Scenarios) × (Iterations) × (API Cost Per Call)
A modest evaluation with 10,000 examples across 10 test scenarios costs $100 per run with a $0.001/call API rate. Make five prompt adjustments requiring complete re-evaluation. That’s $500. Test three different models. $1,500. Add retrieval parameters? The costs compound with each dimension.
The problem gets worse with more sophisticated AI systems. RAG implementations may require multiple LLM calls per test case—one for retrieval, another for generation, and perhaps a third for evaluation. AI agents often make sequential model calls, multiplying your costs at each step. What began as a penny per test case quickly became nickels, dimes, or quarters.
Even more challenging is the feedback loop between evaluation and improvement. When testing reveals issues, you adjust prompts, fine-tune models, or modify RAG parameters. After changes, you must run the entire evaluation suite again to avoid regressions. The cost spiral works like this:
- Initial evaluation identifies issues
- Team makes adjustments
- Full re-evaluation required
- New issues discovered
- Additional adjustments made
- Another full re-evaluation needed
- Repeat until quality targets or budget limits are hit
When you budget for AI projects, you probably focus on development resources and infrastructure, with little allocation for evaluation. The most effective way to reduce costs while maintaining quality is systematic data analysis that helps you focus on what matters. When the true costs emerge, engineering leaders must either request additional funding or compromise on quality. Can we evaluate our AI systems cheaper?
Tiered Evaluation Approaches: Test Broadly, Then Dive Deep
You don’t need to use the entire evaluation dataset for every test run.
We can create a small heuristic dataset that will give us a good signal about the system’s quality. For a comprehensive approach to testing AI systems, you need multiple such datasets. Use the dataset for quick and cheap testing, and then use the full dataset for thorough testing when we have a good candidate for a production-ready solution. There is a small risk of rejecting a good solution because it performs poorly on the heuristic dataset. However, you can mitigate the risk by creating several such datasets and averaging the results or using the anchor points method described later to prune the entire evaluation dataset.
We have several methods of sampling the dataset to create a smaller test suite:
Task-oriented Sampling
Does the AI system have a problem with one particular type of input? If so, you can sample only inputs of a single type. How do we use it?
- Choose a subset of inputs that represent the problem at hand.
- Make it your heuristic dataset.
- Calculate the baseline metric for the heuristic dataset using the current version of your AI pipeline.
- Run experiments with different configurations, models, or parameters to improve the metric.
- If the experiment performance measured using the heuristic dataset is better than the baseline, calculate the metrics using the full dataset.
- If the experiment performance is worse, discard the changes and try a different approach.
Evaluation Dataset Pruning
Pruning is the method of reducing the size of the evaluation dataset while retaining the maximally representative subset from the original dataset. We can use pruning to create the heuristic dataset and still keep the original full dataset for thorough testing, or we can prune the evaluation dataset to have one compressed test set for evaluation.
Data Selection via Importance Resampling
In the “Data Selection for Language Models via Importance Resampling” research paper, the authors suggest using the Importance Resampling method to reduce the evaluation dataset size.
Unfortunately, you cannot create a small dataset from nothing with resampling. In addition to the full evaluation dataset, you need a small dataset of examples, and most likely, you have to create it manually. This small dataset is called the target dataset. The distribution of the target dataset is used to sample the full dataset.
Here is how it works:
- Importance resampling extracts features from both the full dataset (in the paper, called raw dataset) and the example dataset (called target dataset).
- Next, two feature distributions are created, and the importance weights for each example in the raw dataset are calculated.
- The raw dataset is sampled without replacement using probabilities proportional to the importance weights. As a result, we get a smaller dataset that is representative of the target distribution.
You can find the code implementing the data selection via importance resampling in the paper author’s GitHub repository: https://github.com/p-lambda/dsir
Anchor Points Sampling
Anchor Points Method (presented in the “Anchor Points: Benchmarking Models with Much Fewer Examples” research paper) finds a small set of points representative of the full dataset.
The key idea is simple: find a small subset of examples that represent the model’s behavior over the entire dataset. Each anchor point has a weight corresponding to the fraction of the benchmark the anchor point represents. Evaluating models on the anchor points produces a score that rank correlates with performance on the entire benchmark.
Each anchor point is a medoid. A medoid is a representative data point within a cluster. We say it’s representative because the medoid minimizes the average dissimilarity to all other points in its cluster. Usually, when we cluster data, we get centroids. They are the mean values of points in the cluster and don’t correspond to any actual data point. Medoids, on the other hand, are actual data points from the dataset.
Sadly, the authors didn’t publish the code, but the anchor points method is mentioned in yet another research paper: “tinyBenchmarks: evaluating LLMs with fewer examples” and its authors have a repository: https://github.com/felipemaiapolo/tinyBenchmarks. If you want simpler code, use the scikit-learn-extra library and its sklearn_extra.cluster.KMedoids class.
How Many Anchor Points Do You Need?
According to the paper:
Anchor points reliably rank models: across 87 diverse language model-prompt pairs, evaluating models using 1-30 anchor points outperforms uniform sampling and other baselines at accurately ranking models. Moreover, just a dozen anchor points can be used to estimate model per-class predictions on all other points in a dataset with low error, sufficient for gauging where the model is likely to fail.
If the sample size seems too small, consider using silhouette scores. These can help determine the optimal number of clusters in your dataset. You can then use that number for your anchor points.
Adaptive Sampling
The authors of the “Data Efficient Evaluation of Large Language Models and Text-to-Image Models via Adaptive Sampling” paper propose a method of adaptive sampling to select the best sampling technique for the given dataset automatically. Unfortunately, they didn’t release the code, so you can either implement the pseudocode presented in the paper in your favorite language or take a look at the results table in the paper to find the technique that works most of the time.
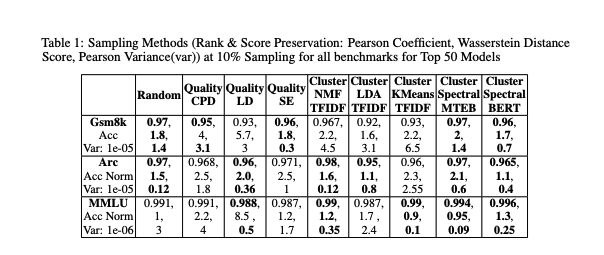
For me, it seems we can get away with using spectral clustering of BERT embeddings to find clusters. Then, we need to sample the clusters. Stratified sampling is a good option, or you can find medoids of the clusters.
Shorten the Prompts. Save Money in Eval and in Production
We have just reduced the number of test cases, but we could also reduce the cost of each test case (and, at the same time, the cost of running the application in production). We need prompt compression.
Prompt compression reduces the number of tokens in the prompt while retaining the output quality comparable to the original prompt. We can split prompt compression techniques into two branches: hard prompt, which eliminates low-information sentences, words, or tokens, and soft prompt, which compresses a series of tokens into a smaller number of special tokens. Both techniques may sound too good to be true, but prompt compression works surprisingly well.
Lossy Prompt Compression
Currently, LLMLingua from Microsoft is the most popular prompt compression open-source library. LLMLingua uses a small language model to transform the verbose original prompt into a compressed prompt with only the most essential information. According to the LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models research paper, the authors were able to achieve 20x compression with only a small performance drop. However, the performance drops sharply around 25x compression:
Our method achieves state-of-the-art performance across all datasets, with up to 20x compression with only a 1.5 point performance drop. Moreover, we observe that LLMs can effectively restore compressed prompts, and prompt compression contributes to a reduction in generated text length. (…) There are also some limitations in our approach. For instance, we might observe a notable performance drop when trying to achieve excessively high compression ratios such as 25x-30x on GSM8K
Still, up to 20 times cheaper AI API calls in both evaluation and production sounds like a good deal. Even 5x compression seems worth the effort.
Lossless Prompt Compression
But we can do better (sort of).
500xCompressor soft prompt compression library can compress up to 500 tokens into one special token. Of course, the method retains information such as proper nouns, names, and numbers, so it’s not always 500x compression. Also, the “500xCompressor: Generalized Prompt Compression for Large Language Models” research paper says, “The results demonstrate that the LLM retained 62.26-72.89% of its capabilities compared to using non-compressed prompts” which isn’t even close to something good enough in production. Yet.
The progress described in the paper is way above the previous best soft prompt compression method, so let’s give them a few months. Maybe one day, we’ll start compressing prompts in production. For now, we can use LLMLingua to eliminate useless words in the prompt.
Sources
- Data Selection for Language Models via Importance Resampling, repository: https://github.com/p-lambda/dsir
- Anchor Points: Benchmarking Models with Much Fewer Examples
- tinyBenchmarks: evaluating LLMs with fewer examples, repository: https://github.com/felipemaiapolo/tinyBenchmarks
- Data Efficient Evaluation of Large Language Models and Text-to-Image Models via Adaptive Sampling, open review version with better algorithm descriptions: https://openreview.net/pdf?id=I8bsxPWLNF
- LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
- 500xCompressor: Generalized Prompt Compression for Large Language Models, repository: https://github.com/ZongqianLi/500xCompressor
- LLMLingua
- LLMLingua2
- KMedoids in
scikit-learn-extra
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn