
We have a database of a fictional telco company providing home phone and internet services to customers in California. We want to build an AI system capable of analizing the data and answering users’ questions about customers, services, and billing. We will design an agentic AI workflow to plan the data retrieval, generate SQL queries, execute the queries, and generate human-readable responses.
Table of Contents
- What Are Agentic AI Workflows?
- Agentic Workflows with LangGraph
- How Do You Use LLama LLM For an Agentic AI Workflow?
- What To Do Next?
What Are Agentic AI Workflows?
An agentic AI workflow is a multi-step process that autonomously handles complex tasks. We build such a process by doing all (or at least some) of the following actions:
-
Breaking down the task into smaller steps. The AI workflow doesn’t try to tackle the whole task at once. Instead, the workflow orchestration code executes a series of simpler prompts. Those prompts gather information required to complete the task, generate parameters for intermediate steps, or define the subsequent action to take. In the end, we synthesize the final result.
-
Defining the next action iteratively. The intermediate steps can be pre-defined by the workflow’s author, but we can also write rules for automatically generating the actions based on the task’s current state.
In such an iterative approach, the AI system consists of an action planning agent, the part executing the action, and a decision-making agent to judge whether the actions were sufficient or if another step is needed.
-
Using multiple specialized AI agents. We don’t have a single prompt encompassing the entire task and all tools available to the AI system. Instead, we break the prompt into smaller parts, each handled by a specialized AI agent. This increases the number of interactions with the LLM, but each interaction is simpler, less error-prone, and easier to debug.
-
Using autonomous action planning and decision-making. The AI workflow doesn’t require human intervention to execute the task. The AI system autonomically decides what to do next based on the task’s current state and the information gathered during the previous steps.
-
Writing advanced prompts such as Chain of Thought or Self-Reflection. We use Chain of Thought or Few-Shot in-context learning to define what the AI agent is supposed to do. Optionally, we can ask the AI agent to review the system’s actions and suggest improvements.
Agentic Workflows with LangGraph
In LangGraph, we can define the agentic AI workflow as a graph consisting of LangChain chains. Each chain represents a single workflow step and usually consists of a single AI interaction (but that’s not a rule). At the end of each step, we return new state variables. LangGraph passes those variables as input to the next step or uses them in conditional statements to decide what to do next.
In our example, we create an agentic AI workflow consisting of the following steps:
- Decide if we can answer the user’s question using the data available in the database.
- Plan what data we need to retrieve.
- Decide if we should continue the workflow. If not, we skip to the step where we explain why we can’t answer the user’s question.
- If we continue, we generate an SQL query to retrieve the data.
- Execute the query and generate a (markdown) text response.
- Generate a human-readable answer for the user’s question using the data retrieved from the database.
As we see above, we have autonomous action planning and decision-making because AI decides what data to retrieve or skip the question if we don’t have access to the required information.
We have also broken the task into smaller steps, each handled by a specialized AI agent. We have an agent capable of generating SQL queries, another agent generating a human-readable response, and an AI agent planning the action.
Executing the query and generating a text response is a step using a pre-defined Python function. Only the function’s input is AI-generated.
How Do You Use LLama LLM For an Agentic AI Workflow?
In this article, I use the llama3-70b model deployed in Llama API. The model is deployed and managed by a third-party service, so I need an API key and a client library.
Instead of using the Llama API SDK, we will change the base URL of the official OpenAI client. Because of that, I can use the tried and trusted LangChain client implementation instead of worrying about bugs in an experimental LLama API Client.
If you want a cheaper model, you can try llama3-8b, but the workflow may not work as expected. When I tested the workflow with the llama3-8b model deployed on Llama API, the response time was too slow, and many requests failed with an Internal Server Error. Still, repeating them to make them pass was sufficient, so I wonder if that’s a problem with the model or the deployment environment. Anyway, a workflow where some of the requests randomly fail is useless unless you add retry logic to all of the AI-agent-invoking functions.
Required Libraries
Before we start, we have to install the dependencies. I used the following libraries:
langchain==0.2.0
langgraph==0.0.50
openai==1.30.1
langchain-openai==0.1.7
I want to use LangSmith for tracking and debugging the requests, so I need two API keys and the LangSmith configuration:
import os
LLAMA_API = "LL-..."
LANGSMITH_API = "lsv2..."
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_ENDPOINT"] = "https://api.smith.langchain.com"
os.environ["LANGCHAIN_API_KEY"] = LANGSMITH_API
os.environ["LANGCHAIN_PROJECT"] = "SOME NAME"
Connecting to a Llama-3 LLM model in LLama API
Now, we import the client and configure the URL and the model name.
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
openai_api_key=LLAMA_API,
openai_api_base="https://api.llama-api.com",
model="llama3-70b"
)
Now, we can use the OpenAI-compatible code with an open-source model. Of course, switching to a different model is not that simple. We will also have to write Llama-compatible prompts, but I will explain the changes when we define the prompts.
Data Preparation
First, we need data in our database. In this article, I will use the Telco Customer Churt dataset from Kaggle. I load the data into a data frame, split the DataFrame into five parts, and store each as a separate table in an SQLite database.
import pandas as pd
import sqlite3
df = pd.read_csv("telco.csv")
df.columns = df.columns.str.replace(' ', '_')
customer_df = df[['Customer_ID', 'Gender', 'Age', 'Under_30', 'Senior_Citizen', 'Married', 'Dependents', 'Number_of_Dependents', 'Country', 'State', 'City', 'Zip_Code', 'Latitude', 'Longitude', 'Population']]
service_df = df[['Customer_ID', 'Phone_Service', 'Multiple_Lines', 'Internet_Service', 'Internet_Type', 'Online_Security', 'Online_Backup', 'Device_Protection_Plan', 'Premium_Tech_Support', 'Streaming_TV', 'Streaming_Movies', 'Streaming_Music', 'Unlimited_Data']]
billing_df = df[['Customer_ID', 'Tenure_in_Months', 'Offer', 'Avg_Monthly_Long_Distance_Charges', 'Avg_Monthly_GB_Download', 'Contract', 'Paperless_Billing', 'Payment_Method', 'Monthly_Charge', 'Total_Charges', 'Total_Refunds', 'Total_Extra_Data_Charges', 'Total_Long_Distance_Charges', 'Total_Revenue']]
referral_df = df[['Customer_ID', 'Referred_a_Friend', 'Number_of_Referrals']]
churn_df = df[['Customer_ID', 'Quarter', 'Satisfaction_Score', 'Customer_Status', 'Churn_Label', 'Churn_Score', 'CLTV', 'Churn_Category', 'Churn_Reason']]
conn = sqlite3.connect('telco.db')
customer_df.to_sql('Customer', conn, if_exists='replace', index=False)
service_df.to_sql('Service', conn, if_exists='replace', index=False)
billing_df.to_sql('Billing', conn, if_exists='replace', index=False)
referral_df.to_sql('Referral', conn, if_exists='replace', index=False)
churn_df.to_sql('Churn', conn, if_exists='replace', index=False)
conn.close()
We will also need a Python function executing a SQL query and returning the result as a DataFrame:
def query_db(query):
conn = sqlite3.connect('telco.db')
try:
return pd.read_sql_query(query, conn)
finally:
conn.close()
Finally, we have to describe the database’s content so AI can decide which columns to use and what possible values they may have.
DB_DESCRIPTION = """You have access to the following tables and columns in a sqllite3 database:
Customer Table
Customer_ID: A unique ID that identifies each customer.
Gender: The customer’s gender: Male, Female.
Age: The customer’s current age, in years, at the time the fiscal quarter ended.
Under_30: Indicates if the customer is under 30: Yes, No.
Senior_Citizen: Indicates if the customer is 65 or older: Yes, No.
Married: Indicates if the customer is married: Yes, No.
Dependents: Indicates if the customer lives with any dependents: Yes, No.
Number_of_Dependents: Indicates the number of dependents that live with the customer.
Country: The country of the customer’s primary residence. Example: United States.
State: The state of the customer’s primary residence.
City: The city of the customer’s primary residence.
Zip_Code: The zip code of the customer’s primary residence.
Latitude: The latitude of the customer’s primary residence.
Longitude: The longitude of the customer’s primary residence.
Population: A current population estimate for the entire Zip Code area.
Service Table
Customer_ID: A unique ID that identifies each customer (Foreign Key).
Phone_Service: Indicates if the customer subscribes to home phone service with the company: Yes, No.
Multiple_Lines: Indicates if the customer subscribes to multiple telephone lines with the company: Yes, No.
Internet_Service: Indicates if the customer subscribes to Internet service with the company: Yes, No.
Internet_Type: Indicates the type of Internet service: DSL, Fiber Optic, Cable, None.
Online_Security: Indicates if the customer subscribes to an additional online security service provided by the company: Yes, No.
Online_Backup: Indicates if the customer subscribes to an additional online backup service provided by the company: Yes, No.
Device_Protection Plan: Indicates if the customer subscribes to an additional device protection plan for their Internet equipment provided by the company: Yes, No.
Premium_Tech_Support: Indicates if the customer subscribes to an additional technical support plan from the company with reduced wait times: Yes, No.
Streaming_TV: Indicates if the customer uses their Internet service to stream television programming from a third party provider: Yes, No.
Streaming_Movies: Indicates if the customer uses their Internet service to stream movies from a third party provider: Yes, No.
Streaming_Music: Indicates if the customer uses their Internet service to stream music from a third party provider: Yes, No.
Unlimited_Data: Indicates if the customer has paid an additional monthly fee to have unlimited data downloads/uploads: Yes, No.
Billing Table
Customer_ID: A unique ID that identifies each customer (Foreign Key).
Tenure_in_Months: Indicates the total amount of months that the customer has been with the company by the end of the quarter specified above.
Offer: Identifies the last marketing offer that the customer accepted, if applicable. Values include None, Offer A, Offer B, Offer C, Offer D, and Offer E.
Avg_Monthly_Long_Distance_Charges: Indicates the customer’s average long distance charges, calculated to the end of the quarter specified above.
Avg_Monthly_GB_Download: Indicates the customer’s average download volume in gigabytes, calculated to the end of the quarter specified above.
Contract: Indicates the customer’s current contract type: Month-to-Month, One Year, Two Year.
Paperless_Billing: Indicates if the customer has chosen paperless billing: Yes, No.
Payment_Method: Indicates how the customer pays their bill: Bank Withdrawal, Credit Card, Mailed Check.
Monthly_Charge: Indicates the customer’s current total monthly charge for all their services from the company.
Total_Charges: Indicates the customer’s total charges, calculated to the end of the quarter specified above.
Total_Refunds: Indicates the customer’s total refunds, calculated to the end of the quarter specified above.
Total_Extra_Data_Charges: Indicates the customer’s total charges for extra data downloads above those specified in their plan, by the end of the quarter specified above.
Total_Long_Distance_Charges: Indicates the customer’s total charges for long distance above those specified in their plan, by the end of the quarter specified above.
Total_Revenue: The total revenue generated from the customer.
Referral Table
Customer_ID: A unique ID that identifies each customer (Foreign Key).
Referred_a_Friend: Indicates if the customer has ever referred a friend or family member to this company: Yes, No.
Number_of_Referrals: Indicates the number of referrals to date that the customer has made.
Churn Table
Customer_ID: A unique ID that identifies each customer (Foreign Key).
Quarter: The fiscal quarter that the data has been derived from (e.g. Q3).
Satisfaction_Score: A customer’s overall satisfaction rating of the company from 1 (Very Unsatisfied) to 5 (Very Satisfied).
Customer_Status: Indicates the status of the customer at the end of the quarter: Churned, Stayed, Joined.
Churn_Label: Yes = the customer left the company this quarter. No = the customer remained with the company.
Churn_Score: A value from 0-100 that is calculated using the predictive tool IBM SPSS Modeler. The model incorporates multiple factors known to cause churn. The higher the score, the more likely the customer will churn.
CLTV: Customer Lifetime Value. A predicted CLTV is calculated using corporate formulas and existing data. The higher the value, the more valuable the customer. High value customers should be monitored for churn.
Churn_Category: A high-level category for the customer’s reason for churning: Attitude, Competitor, Dissatisfaction, Other, Price.
Churn_Reason: A customer’s specific reason for leaving the company. Directly related to Churn Category.
"""
Defining the Workflow Steps
Our workflow consists of five steps. Each step is a LangChain chain and a function that reads the chain’s parameters from the workflow state, executes the chain, and returns the new state.
We define the steps as PromptTemplates and use output parsers to extract the required information from the AI response.
from langchain_core.prompts import ChatPromptTemplate
from langchain.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.output_parsers import JsonOutputParser
LLama-compatible Prompts
If we used the Llama client for LangChain, we wouldn’t have to adapt the prompts (the client library would handle the prompt structure). However, we use the OpenAI client with a modified URL. Because of that, we must follow the Llama prompt structure.
Each prompt must start with the <|begin_of_text|> element. Then, we specify the role of the following message: <|start_header_id|>system<|end_header_id|>. The end of the message is denoted by <|eot_id|>. Additionally, we must end our prompt with the header of an assistant’s response to make the model generate a response: <|start_header_id|>assistant<|end_header_id|>.
Action Planning
For action planning, we need an agent capable of reasoning which columns and tables contain relevant data and deciding whether all required information is available in the database. We will use the Chain of Thought to provide examples of the expected behavior. The agent will respond with a JSON object containing the reasoning and the decision. We will use the reasoning later as an action plan. The decision will be the variable determining whether we continue the workflow.
We have two input variables. One is the user’s question, and the other is the database description we defined earlier. I separate the prompt and the description because it makes the prompt more readable, and we need the description in the next step, too.
can_answer_router_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a database reading bot that can answer users' questions using information from a database. \n
{data_description} \n\n
Given the user's question, decide whether the question can be answered using the information in the database. \n\n
Return a JSON with two keys, 'reasoning' and 'can_answer', and no preamble or explanation.
Return one of the following JSON:
{{"reasoning": "I can find the average revenue of customers with tenure over 24 months by averaging the Total Revenue column in the Billing table filtered by Tenure in Months > 24", "can_answer":true}}
{{"reasoning": "I can find customers who signed up during the last 12 month using the Tenure in Months column in the Billing table", "can_answer":true}}
{{"reasoning": "I can't answer how many customers churned last year because the Churn table doesn't contain a year", "can_answer":false}}
<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["data_description", "question"],
)
can_answer_router = can_answer_router_prompt | model | JsonOutputParser()
def check_if_can_answer_question(state):
result = can_answer_router.invoke({"question": state["question"], "data_description": DB_DESCRIPTION})
return {"plan": result["reasoning"], "can_answer": result["can_answer"]}
Skipping Workflow Steps If the Action Is Not Supported
If the can_answer variable is False, we skip the next steps and return a message explaining why we can’t answer the question. We will need a function returning labels for the LangGraph’s conditional statement. Note that I named the function skip_question, so we flip the logic:
def skip_question(state):
if state["can_answer"]:
return "no"
else:
return "yes"
Generating SQL Queries with AI
Given the question, the action plan, and the database description, we want to generate an SQL query. The following chain defines an AI agent capable of doing so.
write_query_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a database reading bot that can answer users' questions using information from a database. \n
{data_description} \n\n
In the previous step, you have prepared the following plan: {plan}
Return an SQL query with no preamble or explanation. Don't include any markdown characters or quotation marks around the query.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["data_description", "question", "plan"],
)
write_query_chain = write_query_prompt | model | StrOutputParser()
def write_query(state):
result = write_query_chain.invoke({
"data_description": DB_DESCRIPTION,
"question": state["question"],
"plan": state["plan"]
})
return {"sql_query": result}
Executing the SQL Queries
Running the query is a step without an AI agent. We only need a Python function that accepts the SQL query and returns the response as text. In this example, I convert the Pandas DataFrame to a markdown table.
def execute_query(state):
query = state["sql_query"]
try:
return {"sql_result": query_db(query).to_markdown()}
except Exception as e:
return {"sql_result", str(e)}
Generating a Human-readable Response
We have two cases where we have to generate a human-readable response. The first is when the AI agent decides we can’t answer the question due to missing data. The second one is when we successfully retrieved the query results.
Let’s begin with the AI agent generating a response when the data is available:
write_answer_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a database reading bot that can answer users' questions using information from a database. \n
In the previous step, you have planned the query as follows: {plan},
generated the query {sql_query}
and retrieved the following data:
{sql_result}
Return a text answering the user's question using the provided data.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "plan", "sql_query", "sql_result"],
)
write_answer_chain = write_answer_prompt | model | StrOutputParser()
def write_answer(state):
result = write_answer_chain.invoke({
"question": state["question"],
"plan": state["plan"],
"sql_result": state["sql_result"],
"sql_query": state["sql_query"]
})
return {"answer": result}
If we can’t answer the question, we return a message explaining why and apologizing to the user:
cannot_answer_prompt = PromptTemplate(
template="""<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a database reading bot that can answer users' questions using information from a database. \n
You cannot answer the user's questions because of the following problem: {problem}.
Explain the issue to the user and apologize for the inconvenience.
<|eot_id|><|start_header_id|>user<|end_header_id|>
Question: {question} \n
<|eot_id|><|start_header_id|>assistant<|end_header_id|>""",
input_variables=["question", "problem"],
)
cannot_answer_chain = cannot_answer_prompt | model | StrOutputParser()
def explain_no_answer(state):
result = cannot_answer_chain.invoke({
"problem": state["plan"], # the plan contains an explanation of why we can't answer the question
"question": state["question"]
})
return {"answer": result}
Defining an Agentic AI Workflow with LangGraph
A LangGraph workflow requires an object containing the workflow state. We define such an object as a TypedDict. It’s a global mutable state, so do your best not to mess up the state in your workflow.
from typing_extensions import TypedDict
class WorkflowState(TypedDict):
question: str
plan: str
can_answer: bool
sql_query: str
sql_result: str
answer: str
Finally, we can define the workflow:
- First, we create a
StateGraphobject with the state class defined earlier as the type of the state. - Then, we add the function nodes to the graph.
- Set the entry point of the workflow.
- Define edges between the nodes to specify the order of execution.
- Compile the graph to check if it’s correct.
from langgraph.graph import END, StateGraph
workflow = StateGraph(WorkflowState)
workflow.add_node("check_if_can_answer_question", check_if_can_answer_question)
workflow.add_node("write_query", write_query)
workflow.add_node("execute_query", execute_query)
workflow.add_node("write_answer", write_answer)
workflow.add_node("explain_no_answer", explain_no_answer)
workflow.set_entry_point("check_if_can_answer_question")
workflow.add_conditional_edges(
"check_if_can_answer_question",
skip_question, # given the text response from this function,
{ # we choose which node to go to
"yes": "explain_no_answer",
"no": "write_query",
},
)
workflow.add_edge("write_query", "execute_query")
workflow.add_edge("execute_query", "write_answer")
workflow.add_edge("explain_no_answer", END)
workflow.add_edge("write_answer", END)
app = workflow.compile()
Running the Workflow
When we pass the question variable to the workflow, Langraph will execute the workflow autonomously and return the final graph state. One of the state variables will contain the answer:
inputs = {"question": "Count customers by zip code. Return the 5 most common zip codes"}
app.invoke(inputs)
The function returns:
{'question': 'Count customers by zip code. Return the 5 most common zip codes',
'plan': 'I can count customers by zip code by grouping the Customer table by the Zip_Code column and counting the number of customers in each group. Then, I can sort the results to get the 5 most common zip codes',
'can_answer': True,
'sql_query': 'SELECT Zip_Code, COUNT(*) as Count \nFROM Customer \nGROUP BY Zip_Code \nORDER BY Count DESC \nLIMIT 5',
'sql_result': '| | Zip_Code | Count |\n|---:|-----------:|--------:|\n| 0 | 92028 | 43 |\n| 1 | 92027 | 38 |\n| 2 | 92122 | 36 |\n| 3 | 92117 | 34 |\n| 4 | 92126 | 32 |',
'answer': 'Based on the data, the 5 most common zip codes and their corresponding customer counts are:\n\n1. 92028 - 43 customers\n2. 92027 - 38 customers\n3. 92122 - 36 customers\n4. 92117 - 34 customers\n5. 92126 - 32 customers'}
Because we configured LangSmith, we can trace the execution steps in the LangSmith UI:
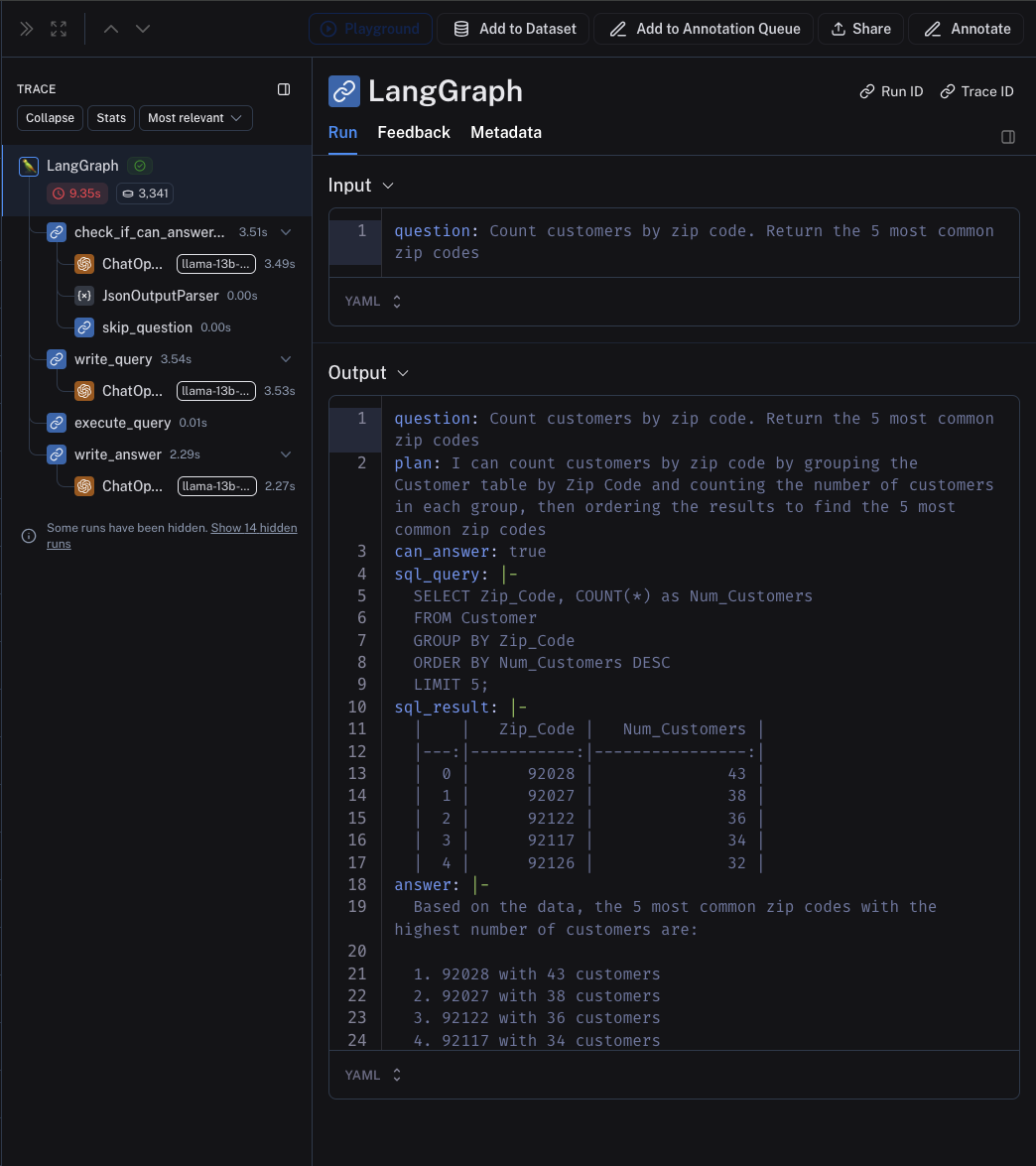
Isn’t It Slow?
The AI workflow needs almost 10 seconds to answer the question. Compared to any other interaction with software, it’s painfully slow. However, I think the response time would be acceptable if we were using the workflow as a chatbot answering simple questions to free up a human data analyst.
Compare it with sending a Slack message to a data analyst. Let’s even assume that the analyst is online, reads the message immediately, isn’t busy and has time to answer right now, knows the database schema by heart, can connect to the database and write the query in a few seconds, and then writes the response. Even in a perfect situation, when all those assumptions are satisfied, a human would need more than 10 seconds to answer the question.
What To Do Next?
Now, you should deploy the workflow. You can use any library capable of running Python code: Flask, Falcon, FastAPI, AWS Lambda Functions, whatever.
In the previous articles, I was deploying my AI Agents as Slack bots or chatbots on a website generated with Streamlit. You can also try LangServe.
Or you can do what seems to be the most popular option nowadays: keep the code in a notebook on a developer machine and never, ever deploy the code in production ;)
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn