
In December 2024, Anthropic released their article on Building effective agents, in which they describe the typical AI workflows and the difference between an AI workflow and an autonomous agent. The Anthropic post is a great theoretical collection of design patterns, but the article lacks practical examples. I’m here to fill that gap.
Table of Contents
- Installation and Configuration of PydanticAI
- What’s the Difference Between AI Workflows and Autonomous Agents?
- Agents and Workflows in PydanticAI
- Prompt Chaining Workflow with PydanticAI
- Routing Workflow with PydanticAI
- Parallelization Workflow with PydanticAI
- Orchestrator-Workers Workflow with PydanticAI
- Evaluator-Optimizer Workflow with PydanticAI
- Autonomous Agent with PydanticAI
- On AI Workflow Design Patterns
We will build every workflow and agent from the Anthropic article using PydanticAI. Additionally, I prepared graphical representations based on the graphics published by Anthropic, focusing on the PydanticAI code used to implement each part of the workflow.
Installation and Configuration of PydanticAI
First, we have to install the PydanticAI library (pydantic-ai, version: 0.0.18) and configure the API key for the LLM provider. I’m going to use OpenAI, so I have to set the OPENAI_API_KEY environment variable. If you use a different provider, follow the instructions on the PydanticAI Model documentation page.
In the code below, if I have imported a module/class in an earlier example, I will not import the module/class again. If you copy code from the middle of the text, you may need to look for missing imports in the text above the code you copied.
What’s the Difference Between AI Workflows and Autonomous Agents?
As Anthropic describes:
AI Workflows are systems where LLMs and tools are orchestrated through predefined code paths.
In a workflow, we use an LLM to accomplish a part of the task, but even if the LLM’s output guides the code execution, AI only selects from the options we provide. Workflows are more predictable and easier to understand. Also, we generally don’t need to worry about getting stuck in a loop while running a workflow (except evaluator-optimizer workflows). Because of their predictability, workflows are often easier to test and deploy reliably.
Autonomous agents are more complex than workflows. They can make decisions independently without being explicitly told what to do. According to Anthropic:
Agents (…) are systems where LLMs dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
We provide tools (functions) to the agent, describe how to use them, and the agent will decide which tool to use. We can include a workflow plan in the prompt. The LLM will likely follow the plan, but there is no guarantee that it will. When your agent doesn’t perform well, you’ll need data-driven techniques to improve its performance.
Agents and Workflows in PydanticAI
In PydanticAI, everything is an Agent. At least, the class used to communicate with the LLM is called Agent. Therefore, in PydanticAI, we have to distinguish between actual agents (Agent instances with tools) and workflow “agents” (Agent instances without tools).
from pydantic_ai import Agent, RunContext
Nothing stops us from building a workflow where some (or all) agents have access to tools, but let’s focus on either pure workflow patterns or AI agents without mixing both concepts.
Prompt Chaining Workflow with PydanticAI
Prompt chaining is a workflow pattern where we decompose the task into smaller parts and use an LLM to accomplish each part. The LLM’s output from one part is used as an input for the next part. Of course, in addition to the output, we can provide additional data and prompts with instructions for subtasks.
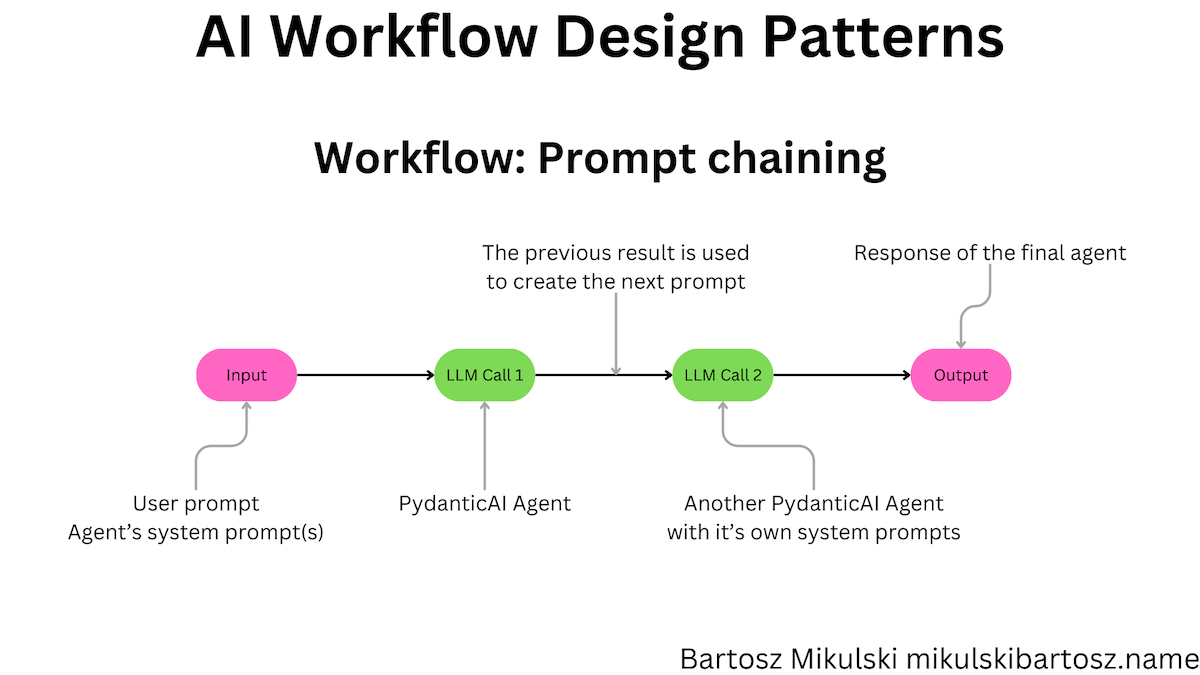
We will implement the prompt chaining workflow to generate a sales email. In the first step, we create an outline of the email. In the second step, we generate the email content based on the outline. We could also split the outline into a single LLM call per outline item. Such a tree-like split is called Hierarchical Content Generation, but let’s not overcomplicate the code.
Before defining the agents, we need to implement classes for input and output data. The input data can be stored in a data class (we can also skip the data class and put the data directly in the prompt without the system-message-building functions). However, we must extend the Pydantic BaseModel class for the output.
Using the BaseModel class is necessary because PydanticAI implementation uses a trick to force the LLM to adhere to the expected data structure. Instead of getting a text response from the AI model, PydanticAI generates a tool for the model to call when the LLM wants to return a value. The tool has a function signature that matches our result class.
from typing import List
from datetime import date
from dataclasses import dataclass
from pydantic import BaseModel
@dataclass
class SalesEmail:
prospect_name: str
product_to_sell: str
product_description: str
deadline_description: str
sales_person: str
sales_contact: str
class OutlineElement(BaseModel):
text: str
class Outline(BaseModel):
elements: List[OutlineElement]
Define the (PydanticAI) Agents
We must define PydanticAI agents for each step of the workflow. We will start with the outline agent.
PydanticAI Agent with Dependencies
A dependency type in PydanticAI means an instance of the class will be available as a variable (if we pass it while using the agent) when PydanticAI generates the system prompt.
outline_agent = Agent(
'openai:gpt-4o-mini',
deps_type=SalesEmail
)
We can include the system message in the Agent constructor, but implementing system-message-building functions is often more convenient. We define system messages as functions decorated with @agent_variable_name.system_prompt. In those functions, we get the RunContext instance, which contains, among other things, the dependency instance.
(Remember to change the decorator’s name when you change the variable’s name containing the agent!)
@outline_agent.system_prompt
def add_the_prospect_name(ctx: RunContext[SalesEmail]) -> str:
return f"The prospect name is: {ctx.deps.prospect_name}."
@outline_agent.system_prompt
def add_the_product_to_sell(ctx: RunContext[SalesEmail]) -> str:
return f"""The product name: {ctx.deps.product_to_sell}
Product description: {ctx.deps.product_description}"""
@outline_agent.system_prompt
def add_sales_person(ctx: RunContext[SalesEmail]) -> str:
return f'The sales person is: {ctx.deps.sales_person}. The client can contact them at {ctx.deps.sales_contact}.'
@outline_agent.system_prompt
def add_the_deadline(ctx: RunContext[SalesEmail]) -> str:
return f'The date today is {date.today()}. The deadline is: {ctx.deps.deadline_description}'
Getting a Response in the Expected Format
Finally, we prepare the dependency instance and run the agent. We have to pass the expected output type to the result_type parameter.
thing_to_sell = SalesEmail(
prospect_name="Alexandra Moon",
product_to_sell="Mystic Serpent Elixir",
product_description="A rare concoction brewed under the light of a blue moon, the Mystic Serpent Elixir is said to grant unparalleled charisma, vitality, and a touch of clairvoyance. Made from the essence of mythical serpents and enchanted herbs, this elixir is perfect for those seeking to unlock their hidden potential.",
deadline_description="This once-in-a-lifetime offer is only available until the next lunar eclipse, so act fast to secure your bottle of Mystic Serpent Elixir!",
sales_person="Evelyn Stardust",
sales_contact="evelyn.stardust@magicalsales.com",
)
result = outline_agent.run_sync("Prepare an outline of the sales email.", deps=thing_to_sell, result_type=Outline)
print(result.data)
Passing the Output to the Next Step
For our second step, we define a PydanticAI agent with its own system prompt which content depends on the output of the first step. We use the Outline class as the dependency for the second agent. The dependency for the second agent is the same class we received as the result type from the first agent (but it doesn’t have to be the same class, we can convert data between steps).
As this is the last step of the workflow and we expect to get a text content, we use the str type for the result type.
email_writing_agent = Agent(
'openai:gpt-4o-mini',
deps_type=Outline,
system_prompt="Write an email using the provided outline."
)
@email_writing_agent.system_prompt
def add_outline(ctx: RunContext[Outline]) -> str:
elements_text = map(lambda x: x.text, ctx.deps.elements)
return "\n".join(elements_text)
@email_writing_agent.system_prompt
def add_style_description() -> str:
return """
Craft this email with the clarity and precision of William Zinsser himself.
Strive for simplicity, avoiding clutter and unnecessary jargon.
Each sentence should carry its weight, contributing directly to the core message.
The tone should be warm and personable, yet direct and authoritative.
Aim for conciseness, ensuring every word earns its place.
Let the language be lean, crisp, and engaging, as if the reader were listening to a trusted friend offering sage advice.
Avoid flowery prose or hyperbole; let the facts and their inherent interest speak for themselves.
Above all, make it clear."""
result = email_writing_agent.run_sync("Write an email.", deps=result.data, result_type=str)
print(result.data)
Routing Workflow with PydanticAI
According to Anthropic, the routing workflow pattern allows for building specialized workflows and using an LLM to decide which workflow to run:
Routing classifies an input and directs it to a specialized followup task. This workflow allows for separation of concerns, and building more specialized prompts.
For example, we can build a RAG workflow where the routing LLM decides from which database we should retrieve the information, and the subsequent workflow steps handle retrieval and output generation for a specific data source. For more advanced RAG techniques, see my article on enhancing RAG system accuracy.
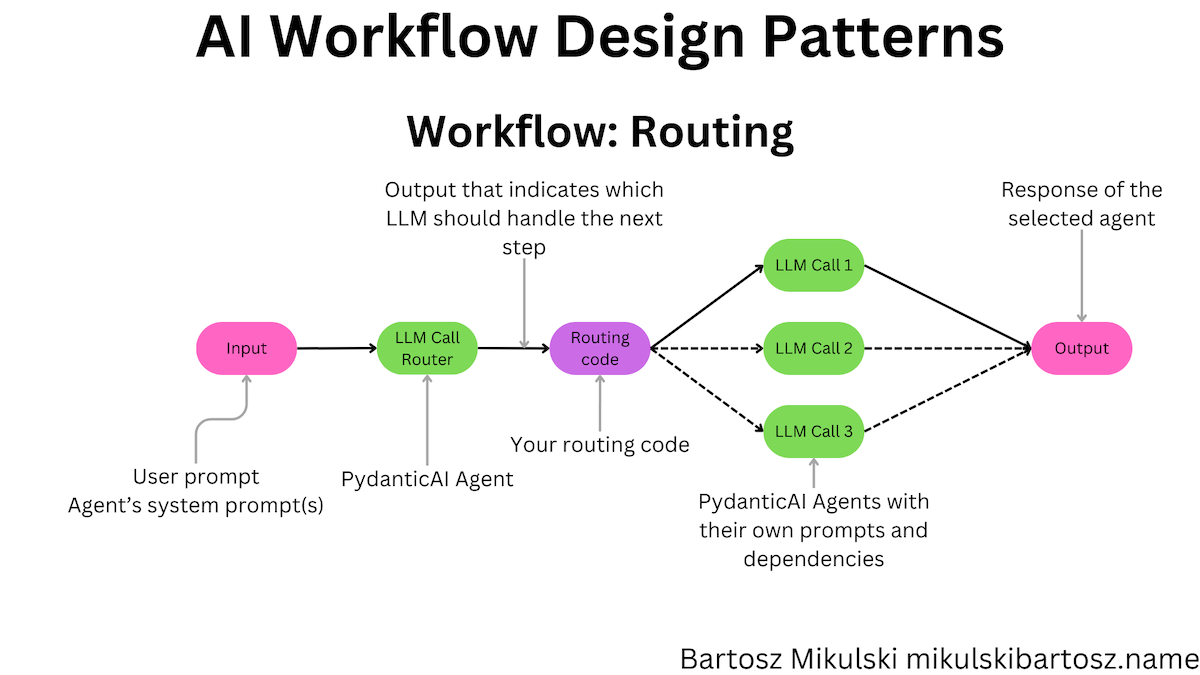
For brevity, I will show you only the routing agent. We can implement the remaining agents as three separate prompt-chaining workflows (or any other workflow pattern).
In the example, we decide which data source may contain the answer to the user’s question. The PydanticAI Agent returns a response type comprising one of the predefined enum types. Depending on the enum value, we decide which code branch to execute:
from enum import Enum
router_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Route the request to the appropriate data source. Data sources available: 'HR', 'Tech support', 'Finance'"
)
class Route(Enum):
HR = "HR"
TECH_SUPPORT = "Tech support"
FINANCE = "Finance"
class RouterDecision(BaseModel):
decision: Route
result = router_agent.run_sync("How do I setup a printer?", result_type=RouterDecision)
if result.data.decision == Route.HR:
...
elif result.data.decision == Route.TECH_SUPPORT:
...
elif result.data.decision == Route.FINANCE:
...
Parallelization Workflow with PydanticAI
We use the parallelization workflow pattern when we split the task immediately and send each part to multiple LLMs. The workflow is helpful in two situations: we can chunk the task into independent parts (without LLMs) and gather the final result from multiple outputs, or we can send the same task to various LLMs to handle the job differently and then use majority voting to decide which output to use.
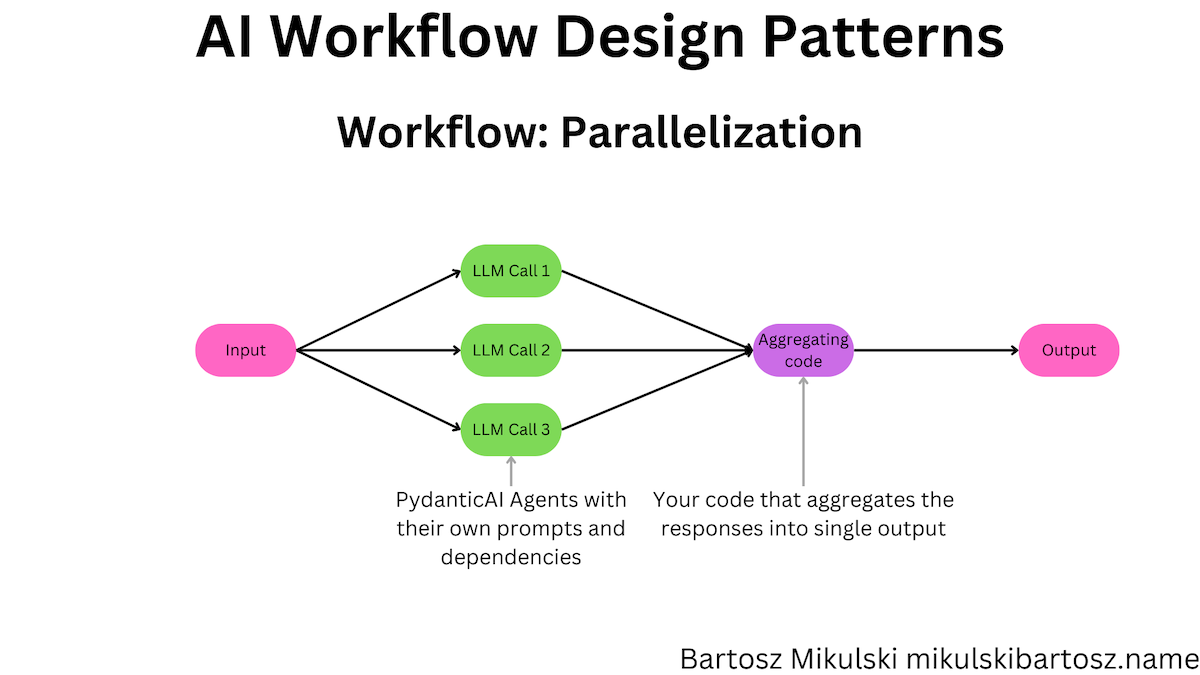
In the example, we have a content moderation workflow for a news website. We want to check the comment posted by the reader before publishing it. We are interested in detecting three kinds of problems: personal data in the comment, hate speech, and comments irrelevant to the article. We can send the same comment to three PydanticAI Agent instances (with three different prompts) and gather the results.
The WebsiteContent class is a dependency for the relevant_agent because the other agents check only the comment and thus don’t need access to the article content.
@dataclass
class WebsiteContent:
title: str
content: str
pii_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Decide if the given text contains Personal Identifiable Information (PII) or not.",
)
hostile_content_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Decide if the given text is abusive or not.",
)
relevant_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Decide if the given comment is relevant to the topic of the commented article or not.",
deps_type=WebsiteContent
)
@relevant_agent.system_prompt
def add_the_title(ctx: RunContext[WebsiteContent]) -> str:
return f"""Title: {ctx.deps.title}.
Content: {ctx.deps.content}"""
Running the Workflow Agents in Parallel
We use asyncio to run the agents in parallel and gather the results. For each task, we need a separate async function. Because we use an async function, we call the PydanticAI run method instead of run_sync.
import asyncio
website_content = WebsiteContent(
title="...",
content="..."
)
comment = "..."
async def run_pii_agent(comment):
pii_agent_response = await pii_agent.run(comment, result_type=bool)
return pii_agent_response.data
async def run_hostile_content_agent(comment):
hostile_content_agent_response = await hostile_content_agent.run(comment, result_type=bool)
return hostile_content_agent_response.data
async def run_relevant_agent(comment, website_content):
relevant_agent_response = await relevant_agent.run(comment, deps=website_content, result_type=bool)
return relevant_agent_response.data
tasks = [
asyncio.create_task(run_pii_agent(comment)),
asyncio.create_task(run_hostile_content_agent(comment)),
asyncio.create_task(run_relevant_agent(comment, website_content))
]
results = asyncio.run(asyncio.gather(*tasks))
Aggregating the Results
The aggregating code gathers the results and decides if the comment should be published. If we want to publish only relevant comments and also filter out comments with personal data or hate speech, we can implement the aggregating code like this:
[contains_pii, contains_hostile_content, is_relevant] = results
publish_comment = is_relevant and not (contains_pii or contains_hostile_content)
Orchestrator-Workers Workflow with PydanticAI
The orchestrator-workers workflow pattern is a combination of the routing and parallelization workflows. We use an LLM to decide which workers to use and then run the workers in parallel. Finally, we gather the outputs and pass them through yet another LLM to get the final result.
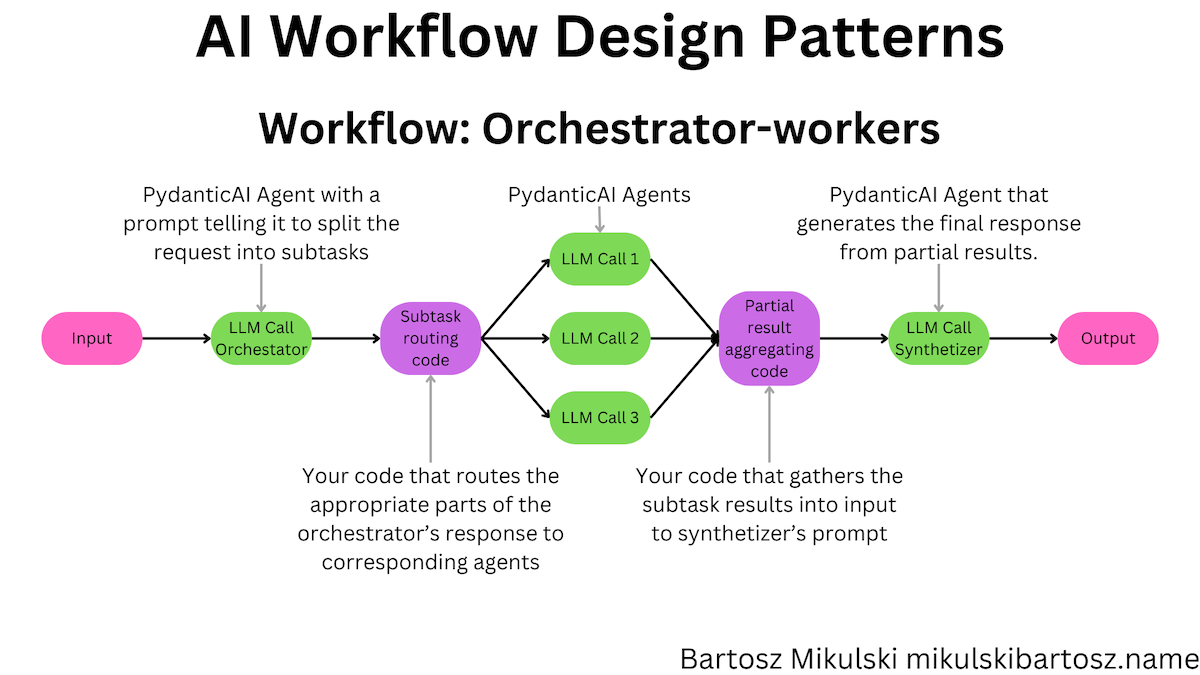
Anthropic suggests using the orchestrator-workers pattern when you cannot predict (without an LLM) which subtasks will be needed.
We will build a workflow to answer employee questions using data from several sources.
Implementing the Orchestrator Worker in PydanticAI
In the orchestrator, we decide which data source to use and what questions we pass to each data source.
orchestrator_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Split the user's question into subquestions appropriate for available data sources. Data sources available: 'HR,' 'Tech support,' 'Finance.' Lists may be empty if the question isn't relevant to the corresponding department"
)
class DatasourceQuestions(BaseModel):
hr: List[str]
tech_support: List[str]
finance: List[str]
question = "If I bring my own printer, can I connect it to the company network, and how will you reimburse me for using my ink?"
result = orchestrator_agent.run_sync(question, result_type=DatasourceQuestions)
print(result.data)
Implementing the Workers for Orchestrator-Workers Workflow in PydanticAI
The worker steps can be separate workflows of any kind or even agents. However, for our example, we will create three workers that dismiss the question and say whatever the employee wants cannot be done.
hr_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Tell the employee they can't do it."
)
tech_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Tell the employee they can't do it."
)
finance_agent = Agent(
'openai:gpt-4o-mini',
system_prompt="Tell the employee they can't do it."
)
Subtask Routing Code
We need a custom code to route the questions to the workers. With asyncio and PydanticAI, we can implement it by running a series of tasks.
async def run_agent(agent, question):
result = await agent.run(question, result_type=str)
return result.data
tasks = []
for question in result.data.hr:
tasks.append(asyncio.create_task(run_agent(hr_agent, question)))
for question in result.data.tech_support:
tasks.append(asyncio.create_task(run_agent(tech_agent, question)))
for question in result.data.finance:
tasks.append(asyncio.create_task(run_agent(finance_agent, question)))
Partial-Result Aggregation
Before passing the worker’s outputs to the synthesizer, we must aggregate the results. As we use asyncio, we can call the asyncio.gather function and then split the results into separate lists by matching the indexes of questions with the results.
results = await asyncio.gather(*tasks)
hr_results = []
tech_results = []
finance_results = []
i = 0
for question in result.data.hr:
hr_results.append(results[i])
i += 1
for question in result.data.tech_support:
tech_results.append(results[i])
i += 1
for question in result.data.finance:
finance_results.append(results[i])
i += 1
Implementing the Synthesizer in PydanticAI
The synthesizer is the last step of the workflow. We pass a dependency containing the original question and the results from the workers. In the system-prompt generating functions, we will use them to build the prompt. We don’t need structured output from the synthesizer, so we use the str type for the result type.
@dataclass
class DatasourceResponse:
original_question: str
hr: List[str]
tech_support: List[str]
finance: List[str]
synthetizer_agent = Agent(
"openai:gpt-4o-mini"
)
@synthetizer_agent.system_prompt
def add_the_original_question(ctx: RunContext[DatasourceResponse]) -> str:
return f"Original question: {ctx.deps.original_question}"
@synthetizer_agent.system_prompt
def add_the_responses(ctx: RunContext[DatasourceResponse]) -> str:
return f"HR responses: {ctx.deps.hr}\nTech support responses: {ctx.deps.tech_support}\nFinance responses: {ctx.deps.finance}"
responses = DatasourceResponse(
original_question=question,
hr=hr_results,
tech_support=tech_results,
finance=finance_results
)
result = synthetizer_agent.run_sync(user_prompt="Write a message to the user's question using responses from other departments", deps=responses, result_type=str)
print(result.data)
Evaluator-Optimizer Workflow with PydanticAI
The evaluator-optimizer workflow consists of a loop where one LLM generates a response to the user’s prompt, and another LLM (or the same one, but in a separate invocation) checks if the response is correct. If the response is incorrect, we pass the feedback back to the generator with instructions to improve the response.
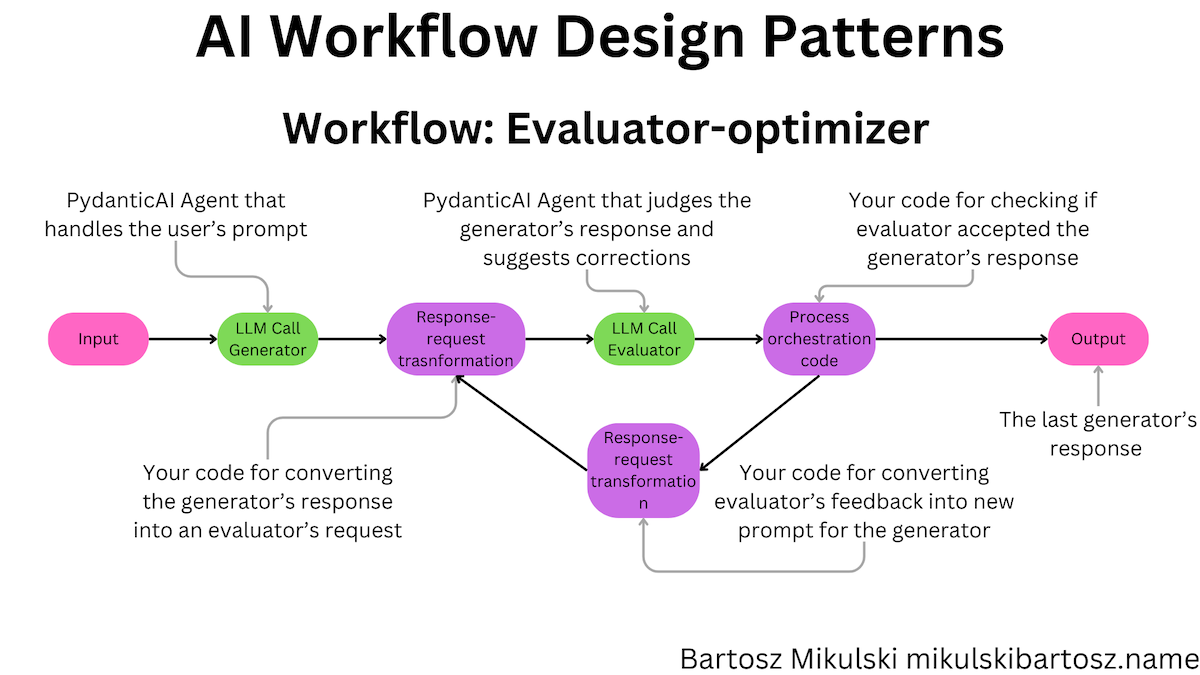
The workflow is useful when the task requires multiple iterations and an LLM is capable of reliably judging the response quality. Anthropic suggests two use cases:
Literary translation where there are nuances that the translator LLM might not capture initially, but where an evaluator LLM can provide useful critiques. Complex search tasks that require multiple rounds of searching and analysis to gather comprehensive information, where the evaluator decides whether further searches are warranted.
We will build a translation workflow, but to make the assignment more interesting and difficult, the evaluator will ask the generator to simplify the translation until it’s easy enough for a person on the B1 level of German to read.
Implementing the Generator for Evaluator-Optimizer Workflow in PydanticAI
Our generator will accept the original text and the feedback from the evaluator. In the first iteration, we will not have the feedback yet, so the system-prompt-generating function has to handle the null value.
class Translation(BaseModel):
translated_text: str
@dataclass
class TranslationFeedback:
original_text: str = ""
translated_text: str = ""
feedback: str = ""
translator_agent = Agent(
"openai:gpt-4o-mini",
deps_type=TranslationFeedback,
system_prompt="Translate the given text to German"
)
@translator_agent.system_prompt
def add_translation_feedback(ctx: RunContext[TranslationFeedback]) -> str:
if ctx.deps.feedback:
return f"Original text: {ctx.deps.original_text}\nTranslated text: {ctx.deps.translated_text}\nFeedback: {ctx.deps.feedback}"
else:
return "No feedback yet."
Implementing the Evaluator for Evaluator-Optimizer Workflow in PydanticAI
The evaluator receives the original text and the proposed translation. The feedback object generated by the evaluator contains the feedback text and a boolean value indicating if the translation is correct.
class Translation(BaseModel):
translated_text: str
class Feedback(BaseModel):
feedback: str
is_translation_correct: bool
translation_evaluator_agent = Agent(
"openai:gpt-4o-mini",
deps_type=Translation,
system_prompt="Evaluate the given translation. Strive to make it understandable for a B1-level learner."
)
@translation_evaluator_agent.system_prompt
def add_translation(ctx: RunContext[Translation]) -> str:
return f"Translated text: {ctx.deps.translated_text}"
We also need our request-orchestration code. The code runs the workflow, converts the data between the formats expected by the generator and the evaluator, and verifies whether the translation has been accepted. Additionally, we must prevent the workflow from running indefinitely, for example, by adding a maximum number of iterations.
text_to_translate = "This is my AI agent. There are many like it, but this one is mine."
# during the first iteration, the feedback is empty
feedback = TranslationFeedback()
number_of_tries = 0
max_number_of_tries = 3
while True:
translator_result = translator_agent.run_sync(text_to_translate, result_type=Translation, deps=feedback)
translation_evaluator_result = translation_evaluator_agent.run_sync(
f"Original text: {text_to_translate}",
result_type=Feedback,
deps=translator_result.data
)
feedback = TranslationFeedback(
original_text=text_to_translate,
translated_text=translator_result.data.translated_text,
feedback=translation_evaluator_result.data.feedback
)
if translation_evaluator_result.data.is_translation_correct:
print("Translation correct.")
break
if number_of_tries == max_number_of_tries:
print("Max number of tries reached.")
break
number_of_tries += 1
Autonomous Agent with PydanticAI
Finally, we can talk about the autonomous agents. According to the Anthropic article, autonomous agents are perfect when:
Agents can be used for open-ended problems where it’s difficult or impossible to predict the required number of steps, and where you can’t hardcode a fixed path.
Agents use tools, which are functions we provide to them. The function description becomes a part of the LLM’s prompt! If the agent fails to use the tool correctly, you should tweak the tool description or provide examples in the in-context learning fashion.
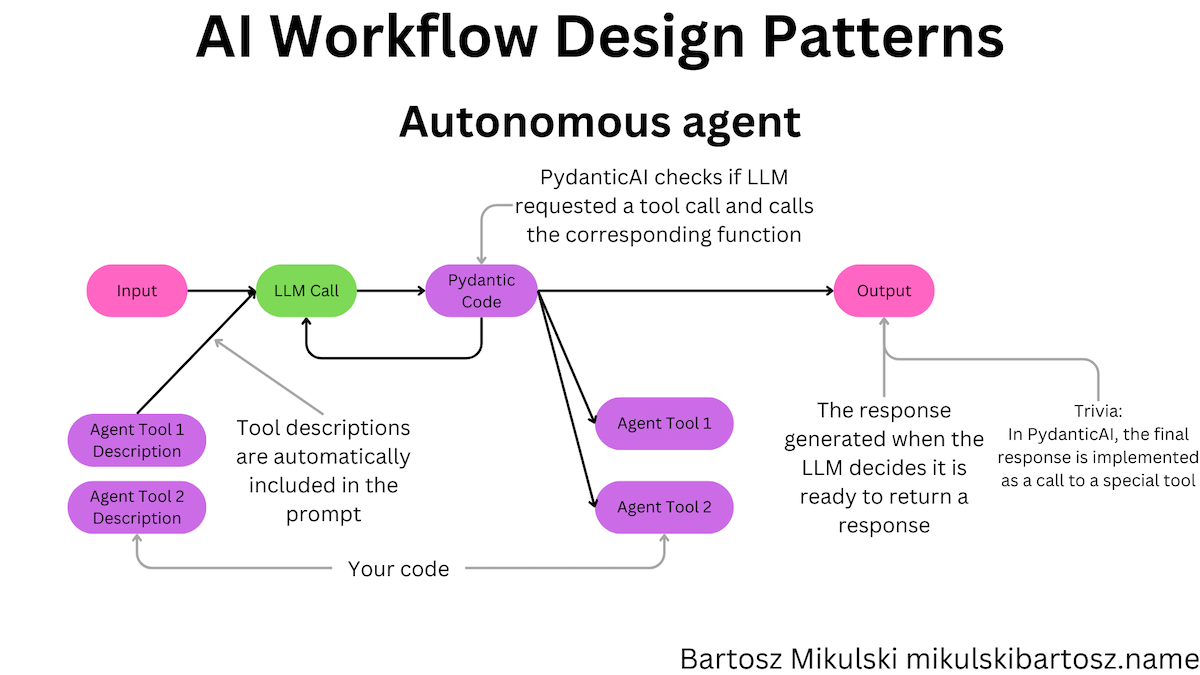
Let’s build an autonomous agent capable of generating and running Python code.
WARNING! The code below is just the simplest example that could possibly work. It has no guardrails and will run any code generated by the LLM. ANY CODE. Including code that modifies or deletes files on your computer.
We use the tool_plain decorator to define the tool when the tools don’t require data from PydanticAI RunContext. The function’s doc-string becomes the tool’s description and is included in the LLM’s prompt.
run_code_agent = Agent(
"openai:gpt-4o-mini",
system_prompt = """Generate and run Python code to fulfill the user's request.
The only way to return a value from the code is to print it to the standard output!
Always print to stdout."""
)
@run_code_agent.tool_plain
def run_python_code(code: str) -> str:
"""Run the given Python code and returns the stdout content as the result."""
import subprocess
import sys
try:
result = subprocess.run(
[sys.executable, '-c', code],
text=True,
capture_output=True,
check=True
)
stdout = result.stdout
return stdout
except subprocess.CalledProcessError as e:
return f"Error: {e.stderr}"
run_code_agent.run_sync("List the files in the /content/sample_data directory.", result_type=str)
On AI Workflow Design Patterns
Over the last two years, we have used LLMs in various domains. We have generic AI workflows, Retrieval Augmented Generation workflows, and Autonomous Agents. It’s good to see that some usage patterns emerge as we switch from experimentation to production. As with every design pattern, it’s essential to understand the trade-offs, proper usage, and the limitations. During my career, I have seen way too many developers thinking patterns are Pokemons, and they must catch them all. Don’t be one of them.
Go From AI Janitor to AI Architect
Stop debugging unpredictable AI systems. I can help you build, measure, and deploy reliable, production-grade AI applications that don't hallucinate.
Message me on LinkedIn